

Layout
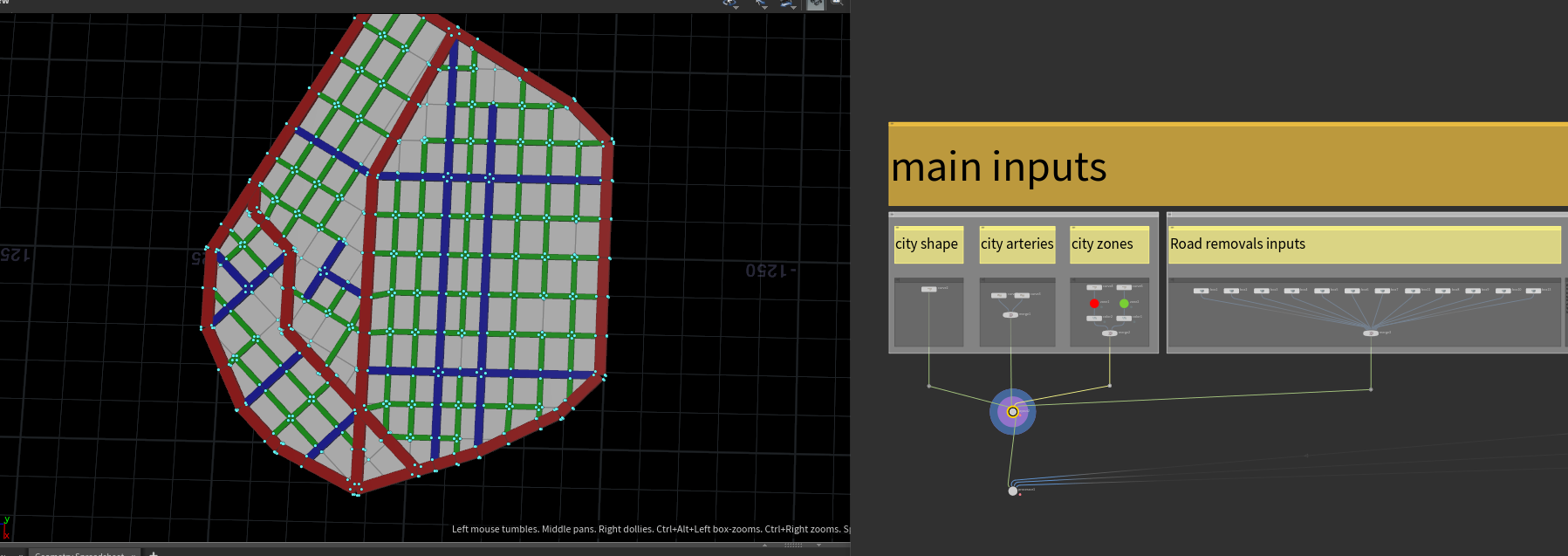
输入共4个 :
城市的底座 、城市的主路 、城市的高度 、 道路阻挡块
输出2个:
一个可视化 、 一个综合数据Pack集
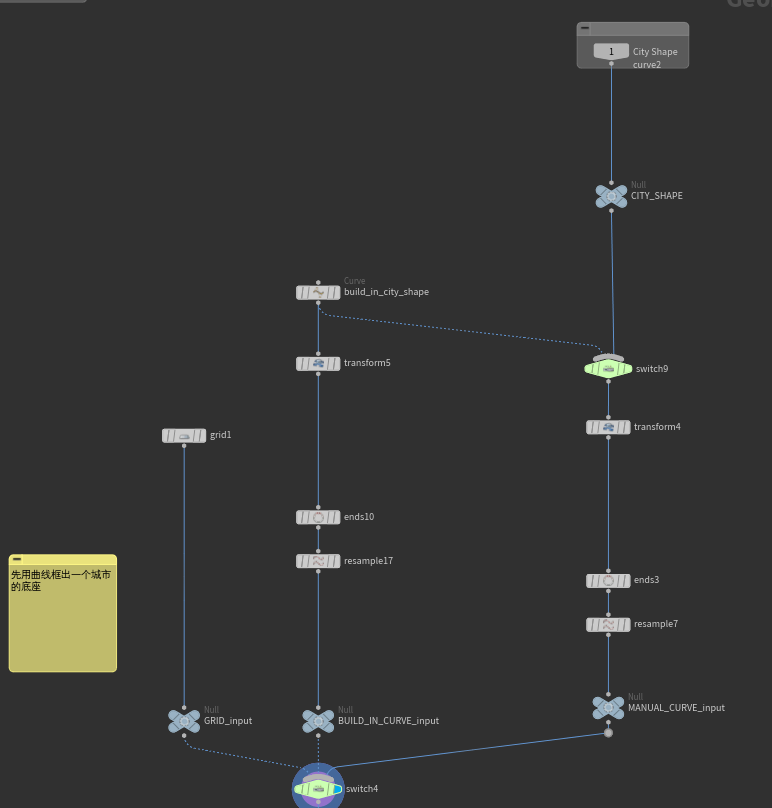
进去第一部分就是用线框出一个城市的底座,支持三种不同类型输入
接下来switch 有两种路线一种是用divide细分的方式,旋转细分。
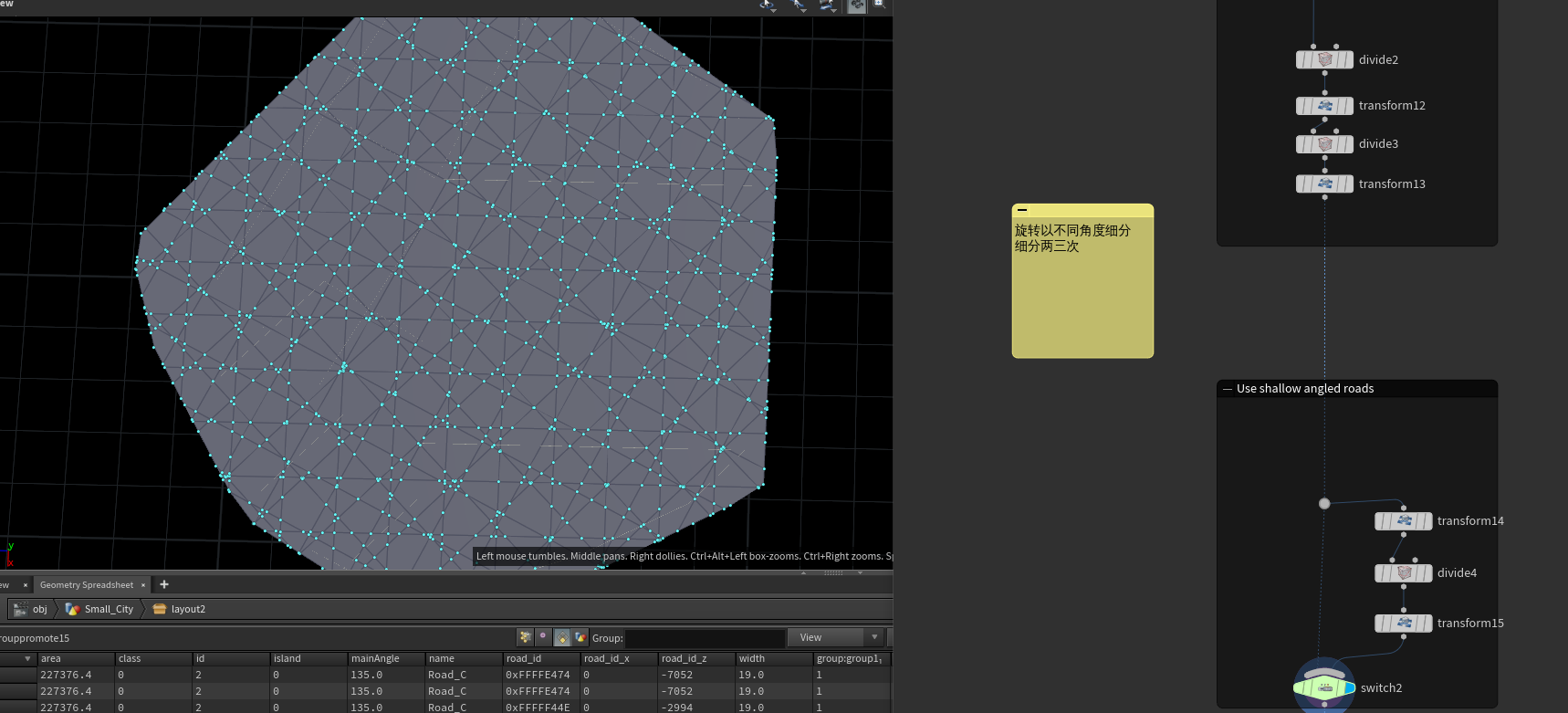
另一种是先获得一个简化后的形状,这一步先细分,提取边缘片删除,只保留内部规整的矩形,转为边缘线段,提取线段长度小于细分大小+10的线段,再遍历每一块内部线段,看看每一块由多少线段组成,如果是偶数便删除最后一个prim,奇数则不用,最后再将中间的点输出只保留头尾。将断的部分给连起来,可以选择用凸包来代替形状,这样就得到一个简易的形状(过程一点不简易好伐:)。
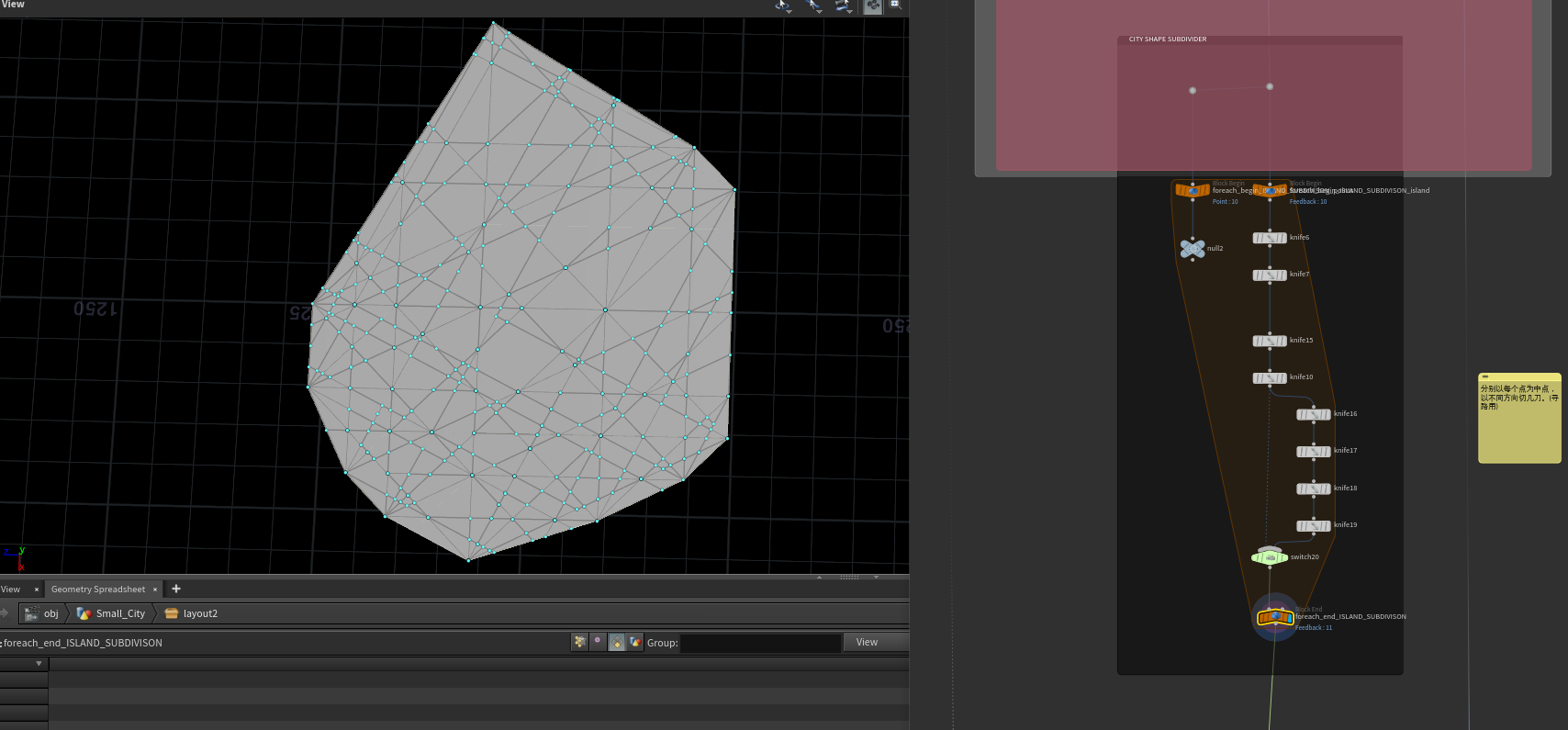
最后在以这个形状每个点为中点 一个点切几刀,最后切出这个形状。
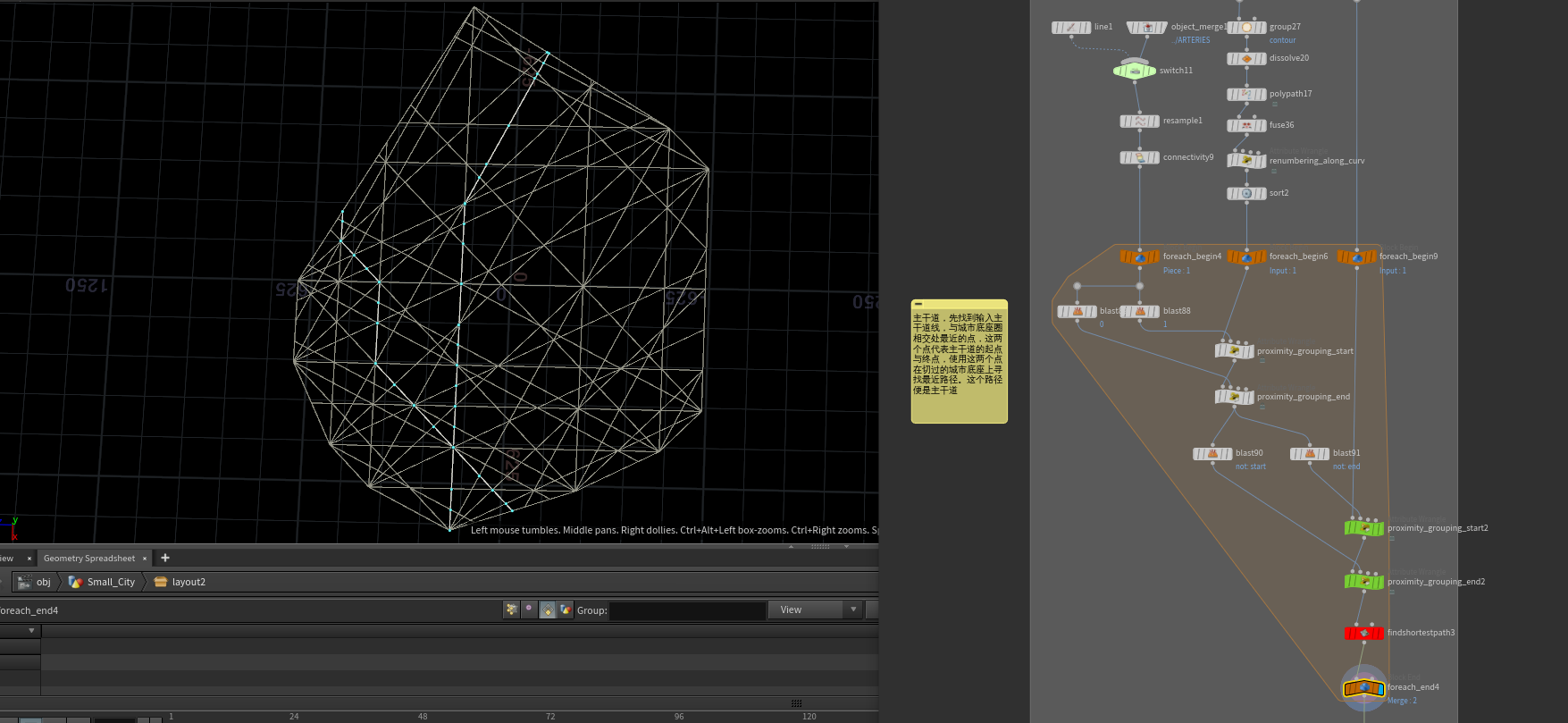
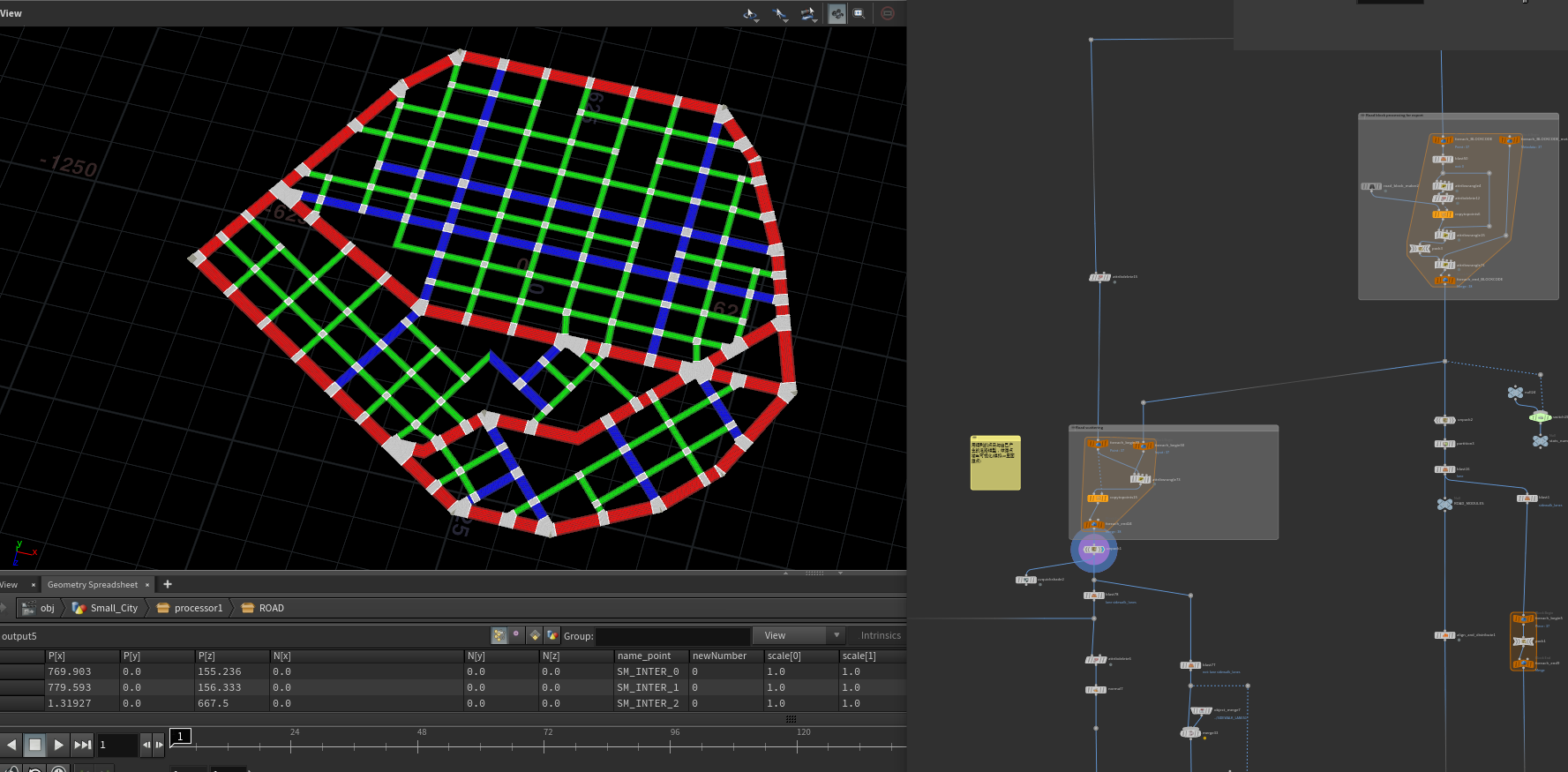
接下来就通过这个形状来找主干道,先找到输入主干道线,与城市底座圈相交处最近的点,这两个点代表主干道的起点与终点,使用这两个点在切过的城市底座上寻找最近路径。这个路径便是主干道。
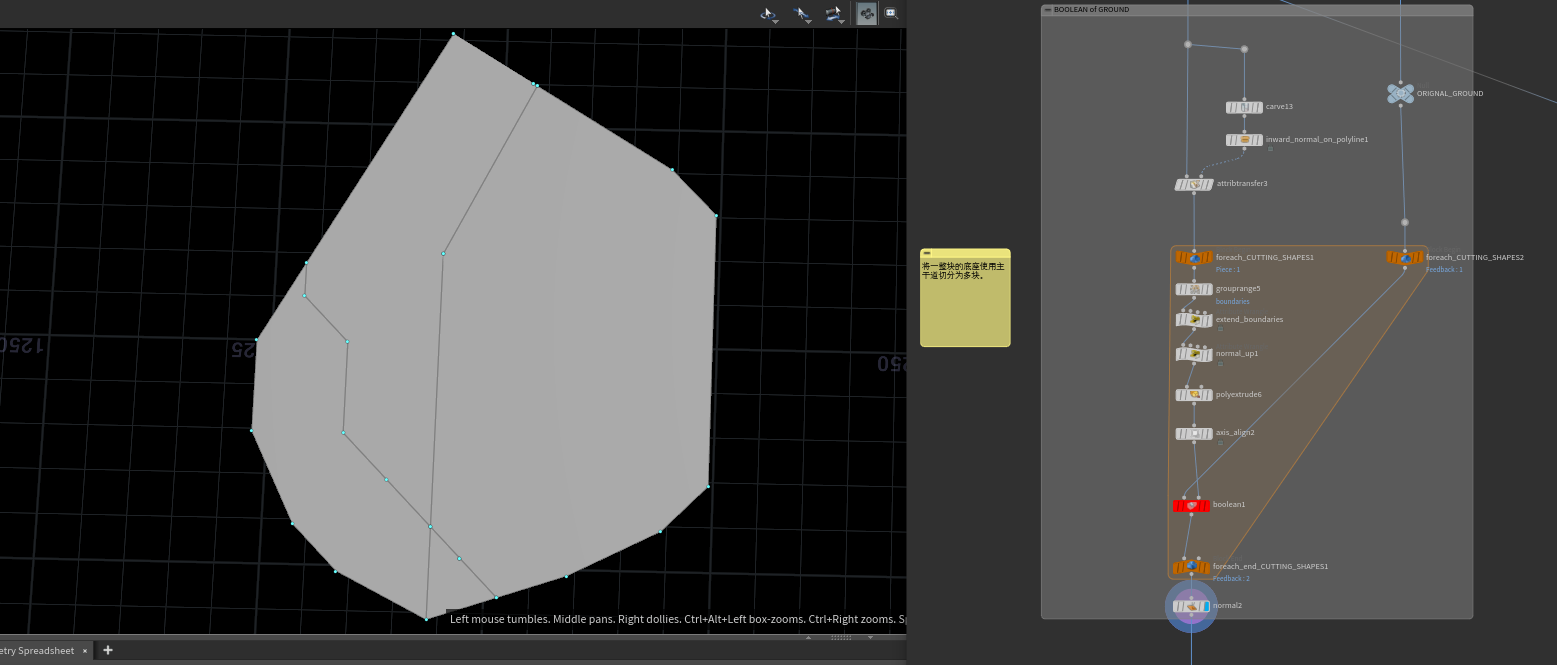
然后使用主干道将一整块的底座使用主干道切分为多块prim。
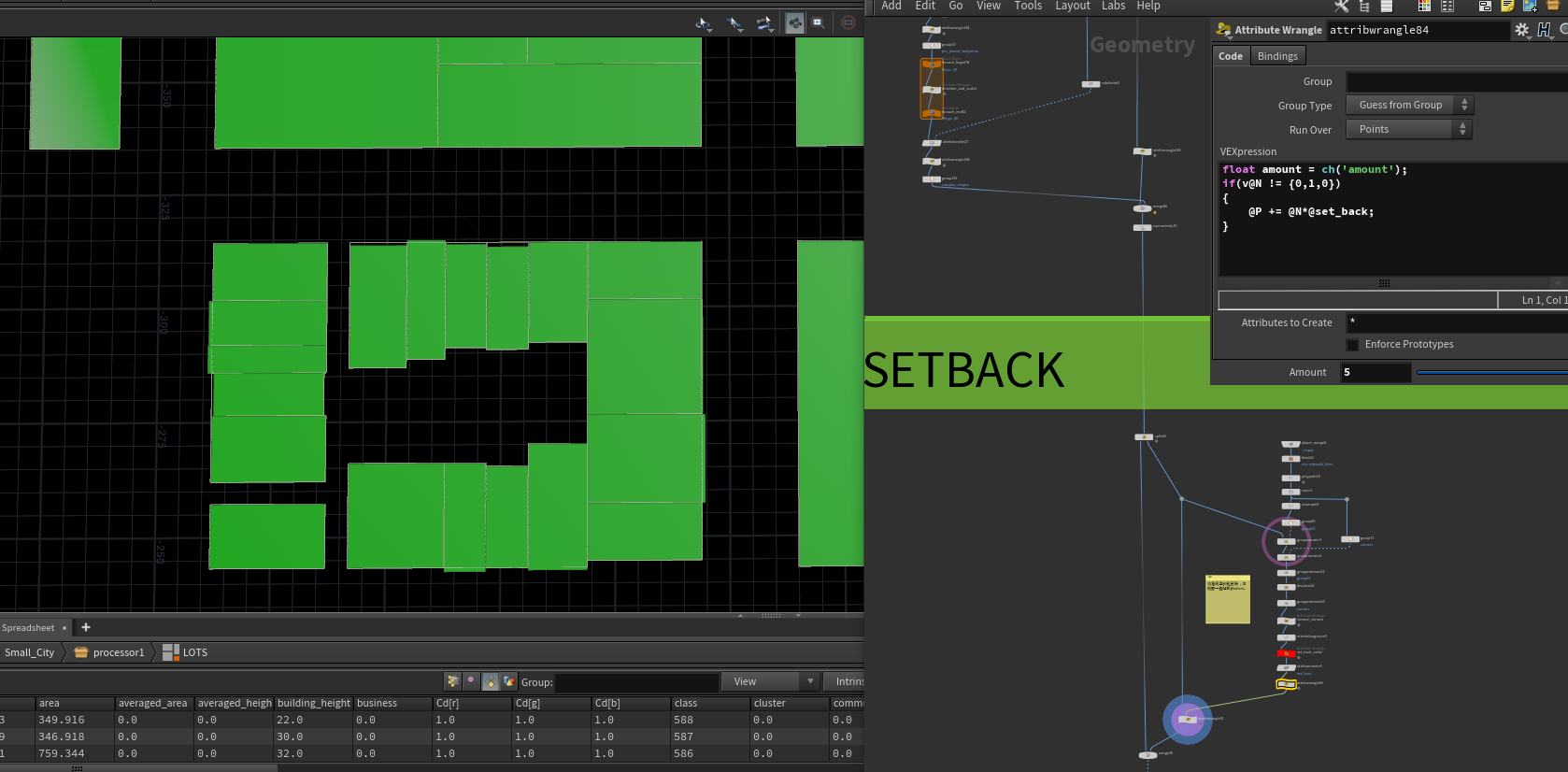
接下来就是清理一下这些块数据 ,因为这些块是用Boolean切分的可能不感觉,并且提取大块小块,判断条件为面积大于50000,然后循环每一块找它们的最长边并算出最长边旋转到坐标水平轴的夹角。等下好按照这个夹角去旋转这个面,让最长边平行与Z轴,每隔一段切一刀,在让其平行与Z轴继续隔一段切一刀。
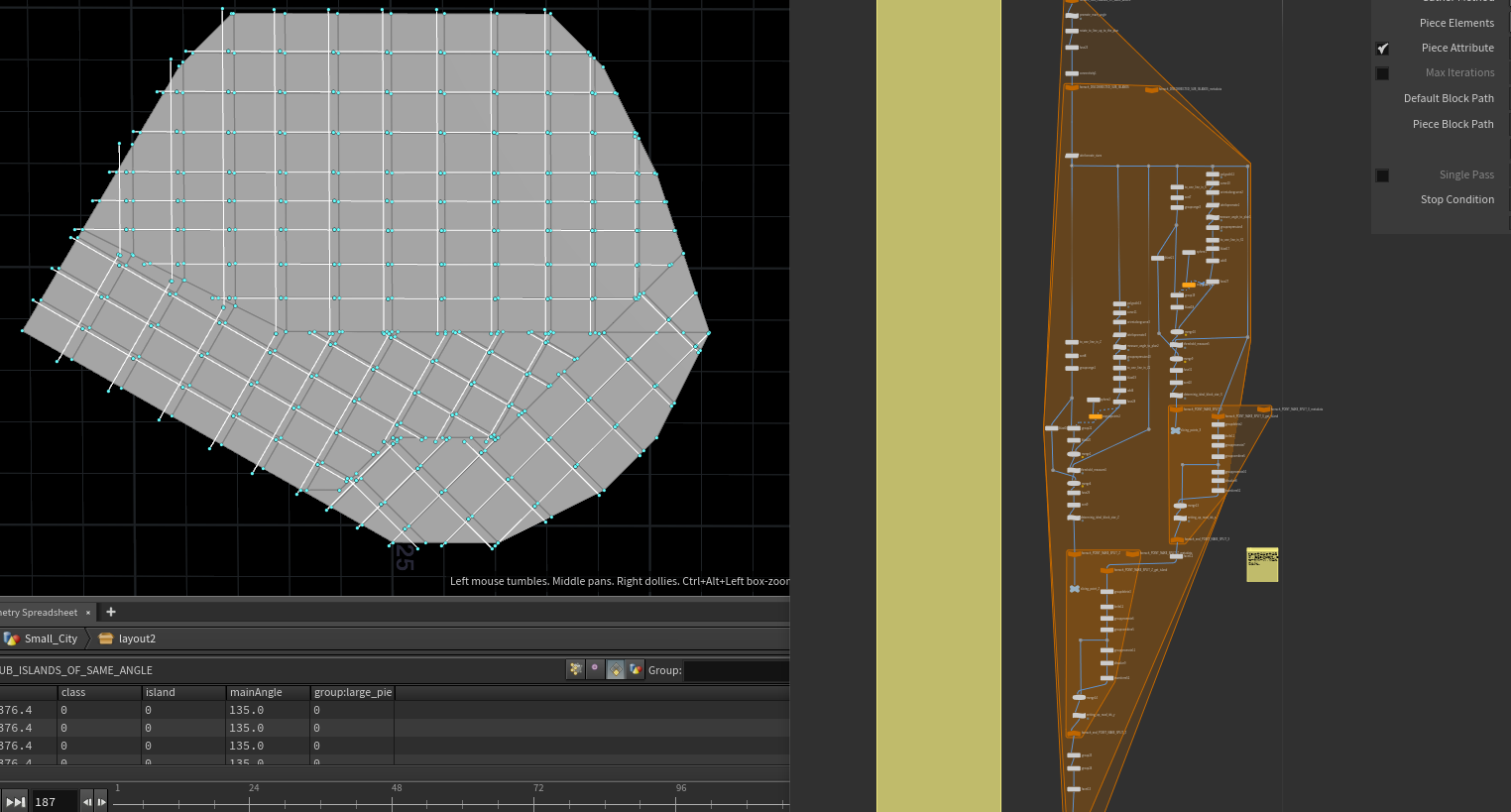
切的时候就分配了 B道路 ,逻辑就是先把这个输入面对应切方向的轴 缩放为0,就变成一列点,这些点就是切B级道路的,然后这些点剔除大于一定范围的点,剩下点将fuse,这些就是保留的B级道路点,C级道路点便是根据B级的距离生成的。(这段需要自己细看内部实现,我只说大概)
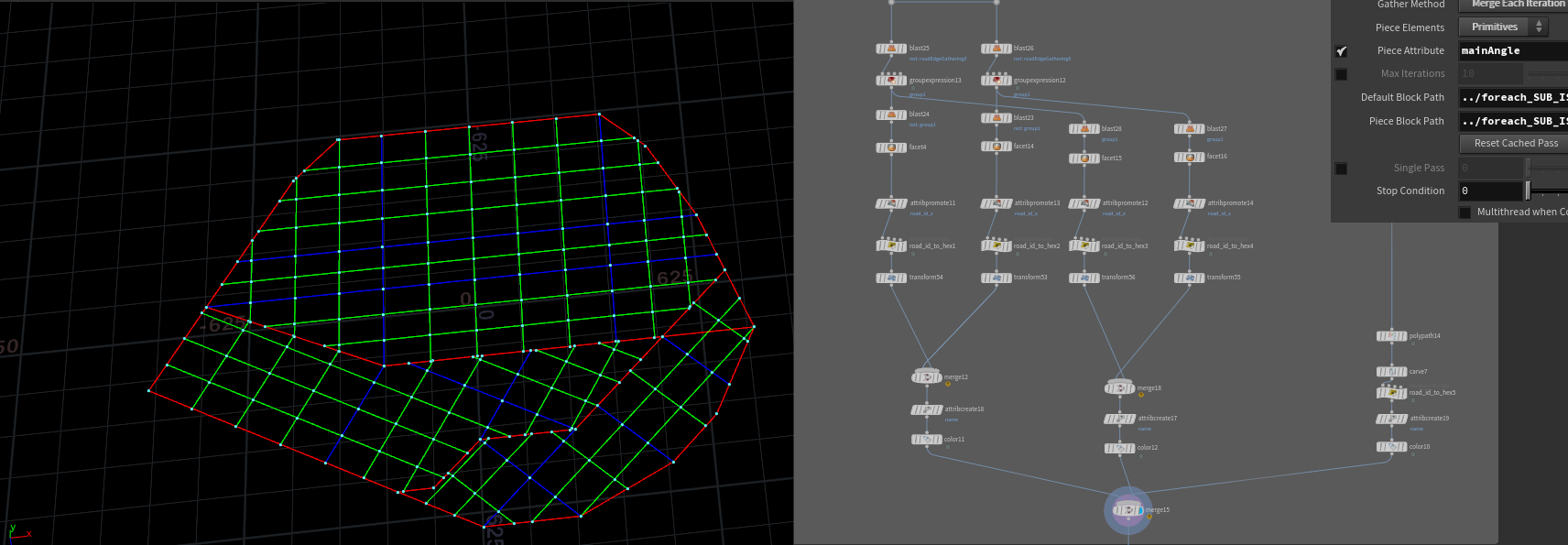
将ABC三种道路分别附上对应属性 名字 id 宽度,在根据宽度做相交剔除,离比自己高级的道路太近的道路线段将会被剔除,
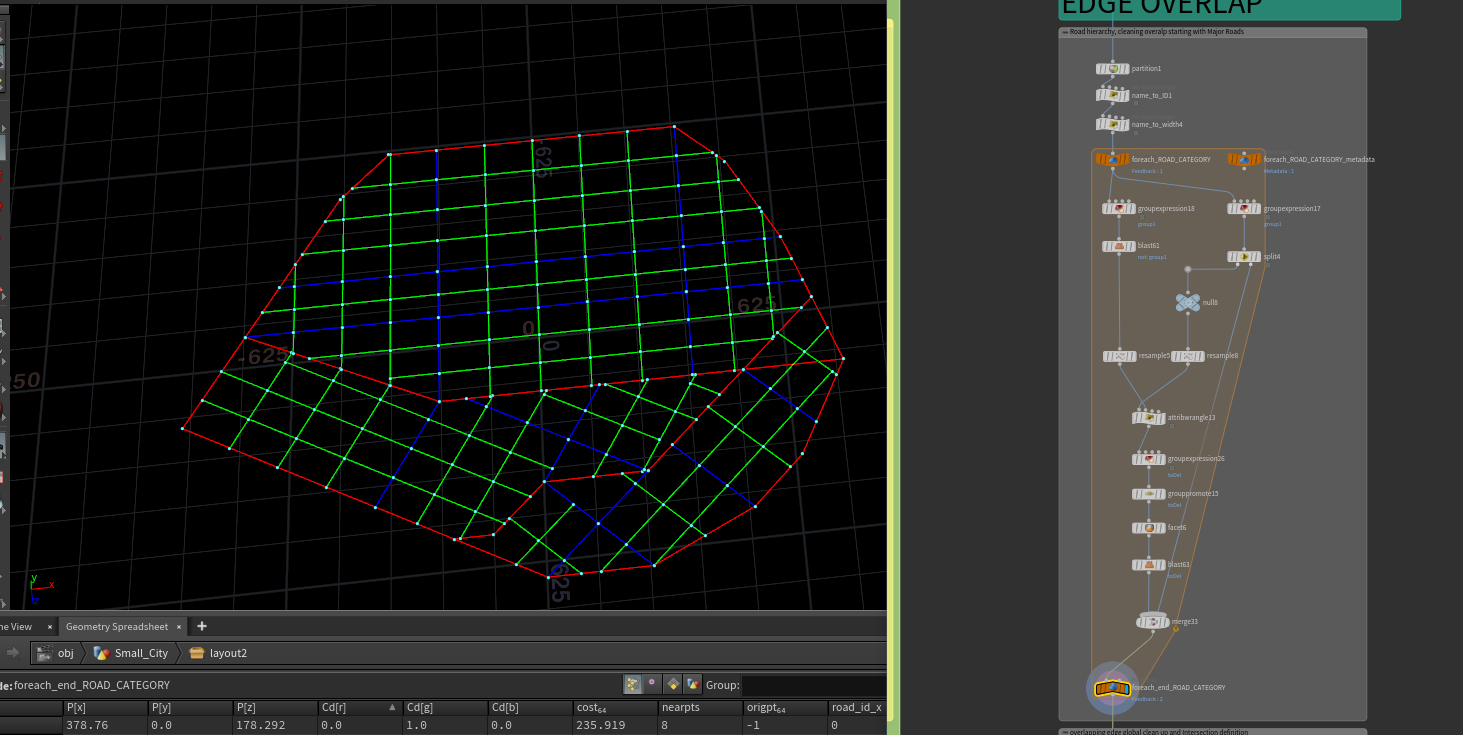
先细分为点判断距离,在由点转到线段prim上判断是否剔除。
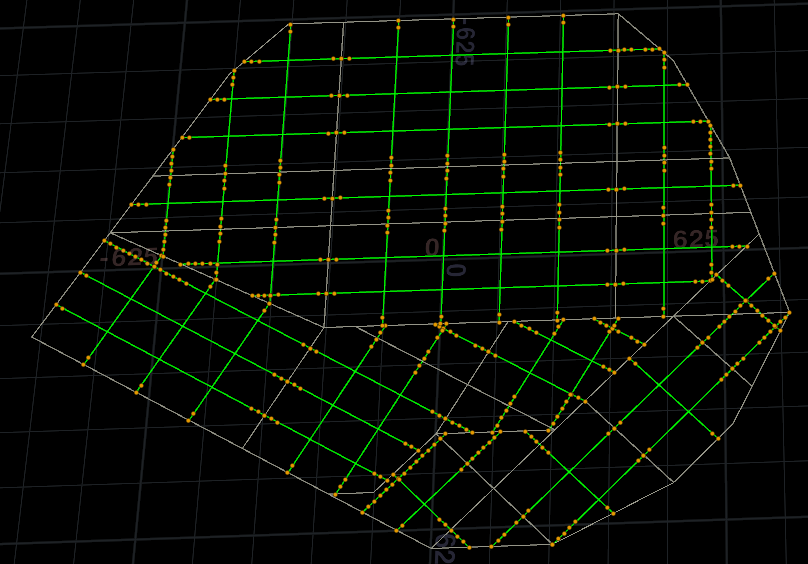
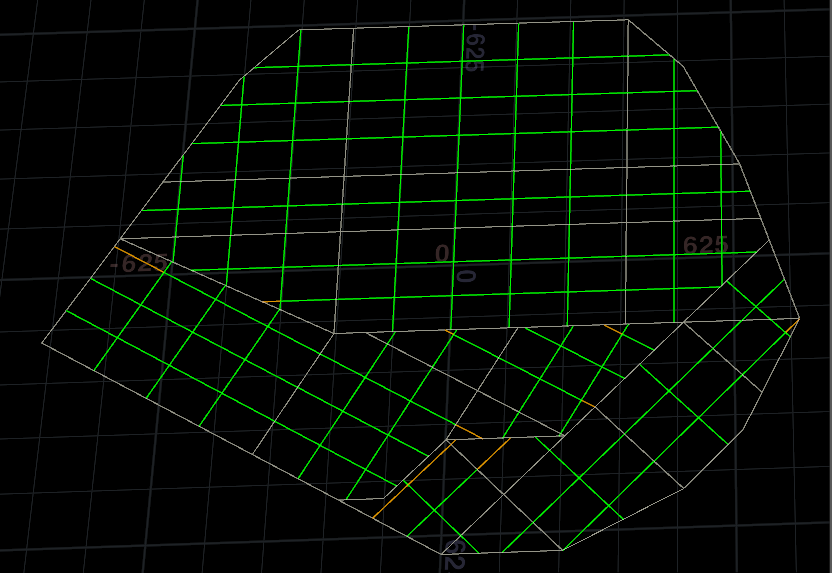
然后清理边缘重叠与计算道路线段与输入4道路阻挡块的相交,如果当前道路段包含在阻挡块中就剔除。
然后删除太小的路,还有删除离主干道太近的路,然后继续剔除在阻挡块中的路段,再清理线段
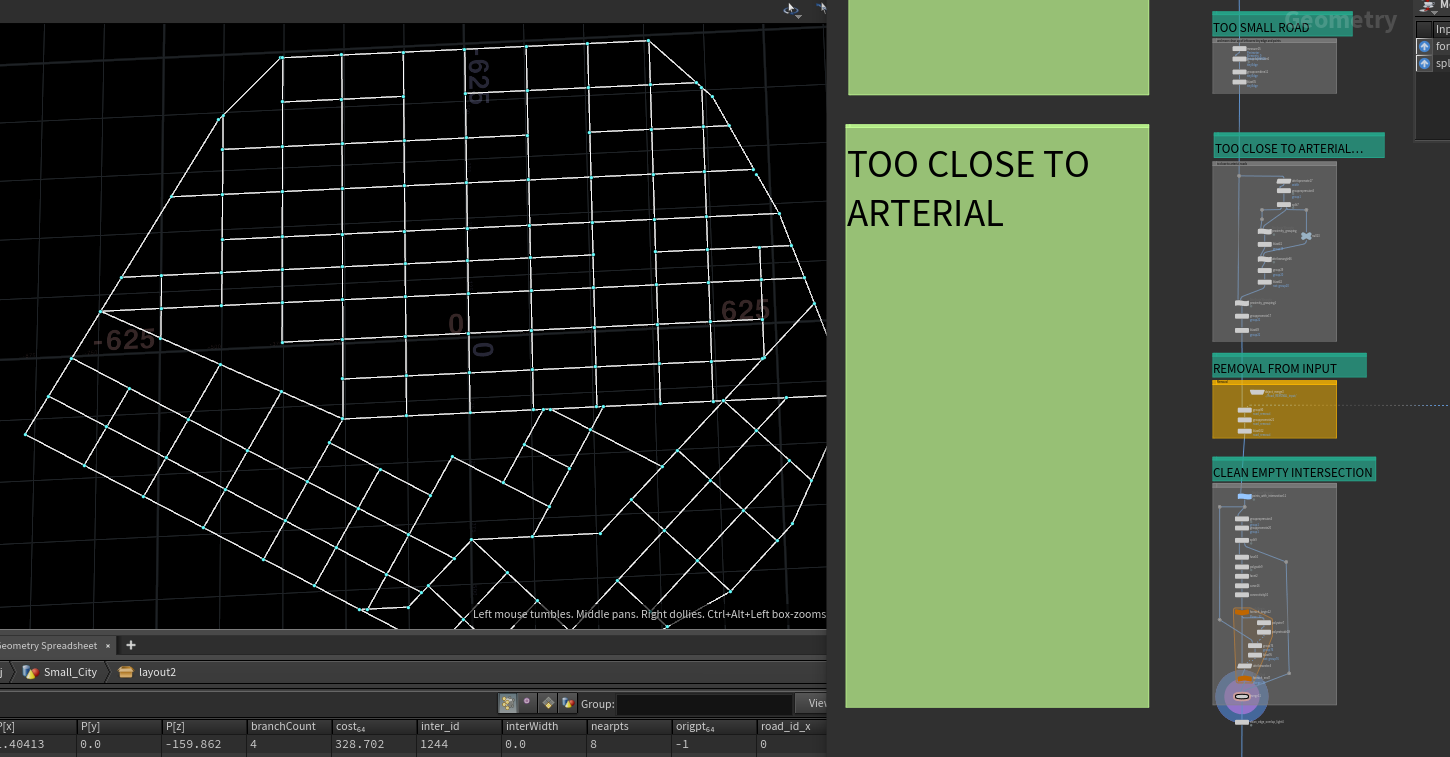
重新再根据路段name附上属性,接下来将距离比较近的路口融合起来,设置属性和再次继续剔除在阻挡块中的路段,再清理和修复线段属性,这时候基本就能拿到一个最终的道路曲线,有了道路曲线我们的输出1和输出2就基于这道路曲线。
输出1:将道路曲线按照自身的宽度属性与位置,生成一个新的prim道路片,再将道路片polyextrude挤出,就能得到基础的道路样子,再翻转顶点与重新计算法线 与 我们切分道路时产生的底座合并输出便可以。
输出2:输出2是由多个输出组合起来分别是 lot底座布局、sidewalk人行道、底座形状、road_network路网、city_metadata城市的元数据。
road_network路网数据不用说就是我们最后拿到的道路曲线给上一个Group便可以啦。
底座形状便是通过我们的road_networdk路网做一个凸包,取这个包围盒的正面既可。
lot底座可以理解为街道块挤出与底座做一个boolean操作得到。
但是这个底座这边有一个要注意的地方,就是把边缘的点给标记出来啦,逻辑就是生成两个道路片 A 、B,A按照正常道路宽度生成,B按照正常(道路宽度-1)生成,然后A算 xyzdist(B,@P,prim,uvw);,如果重叠的地方就是0,如果边缘的地方就不重叠 距离为1。下面就可以根据距离将边缘点提取出来,每个边缘点按照N方向生成一条线(N就是街道的方向),再取他们的相交点就是fuse的位置。就能缝合这种边缘。boolean得到的底座进行一个数据清理与法线计算便可以了。
sidewalk人行道:人行道我们可以用polypath把lot底座的边缘提取出来,遍历road_network每一条道路,将道路属性转移到对应附近的人行道到,有了道路属性的人行道线段就可以输出啦。
city_metadata城市的元数据就是我们切分道路时产生的底座附上各种城市的元数据(高度呀等等)就可以啦。
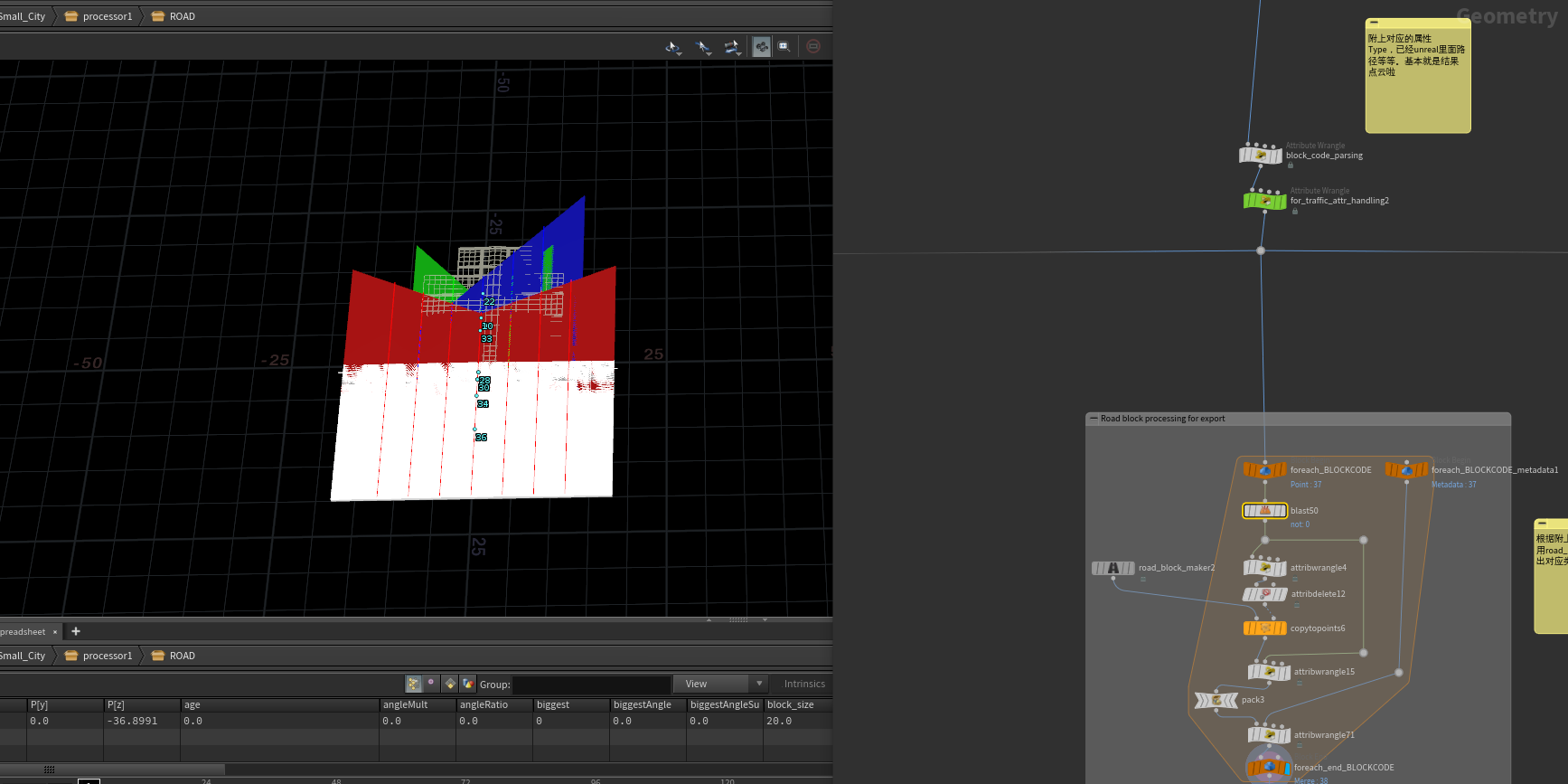
processor-Road
到路这一部分啦,这一个HDA的主要输入就是城市Layout的复合输出,我们主要用到道路,就主要把道路线段blast出来处理,
拿到道路线段之后,我们先要计算与得到一些数据给之后的解算用,首先我们计算交叉路口每个点的属性,包括每个点法线与其他点法线的最大角度,最小角度,与水平轴的角度,用最大角度作为顺序属性等等。
再把道路相近的点融合变成一个交叉路一个点,这个点取所以点的交叉路口数最大值,道路宽度最大值。不同宽度给上不同颜色。分离出大于三个分支的、边缘有其他点的、角落点的道路相交点给之后的交叉路口解算器用, 分离出的点 叫点 S 吧
道路交叉解算器这边先拿到原始的道路线段数据将每一段道路从中间分为两段,每段都和 分离出的点S 在同样位置width米内就保留否则剔除,遍历每条分割后的道路线段。(width为路的宽度属性)
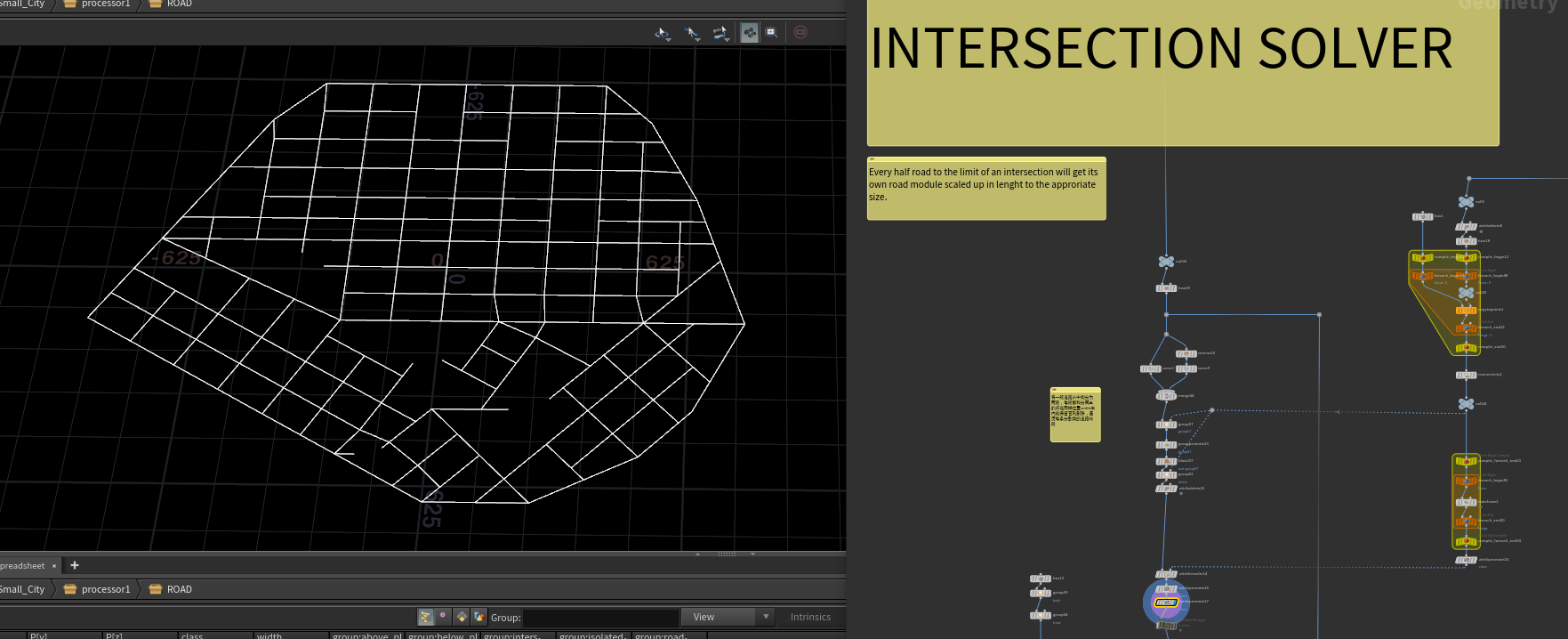
为每个分割后的道路线段的交叉路交点copytopoints一个box,box的
scale={@width,1,@perimeter}
@perimeter 就是与这条道路最近的相交道路宽度。
将copy的点云与copy得到的模型一起输出。
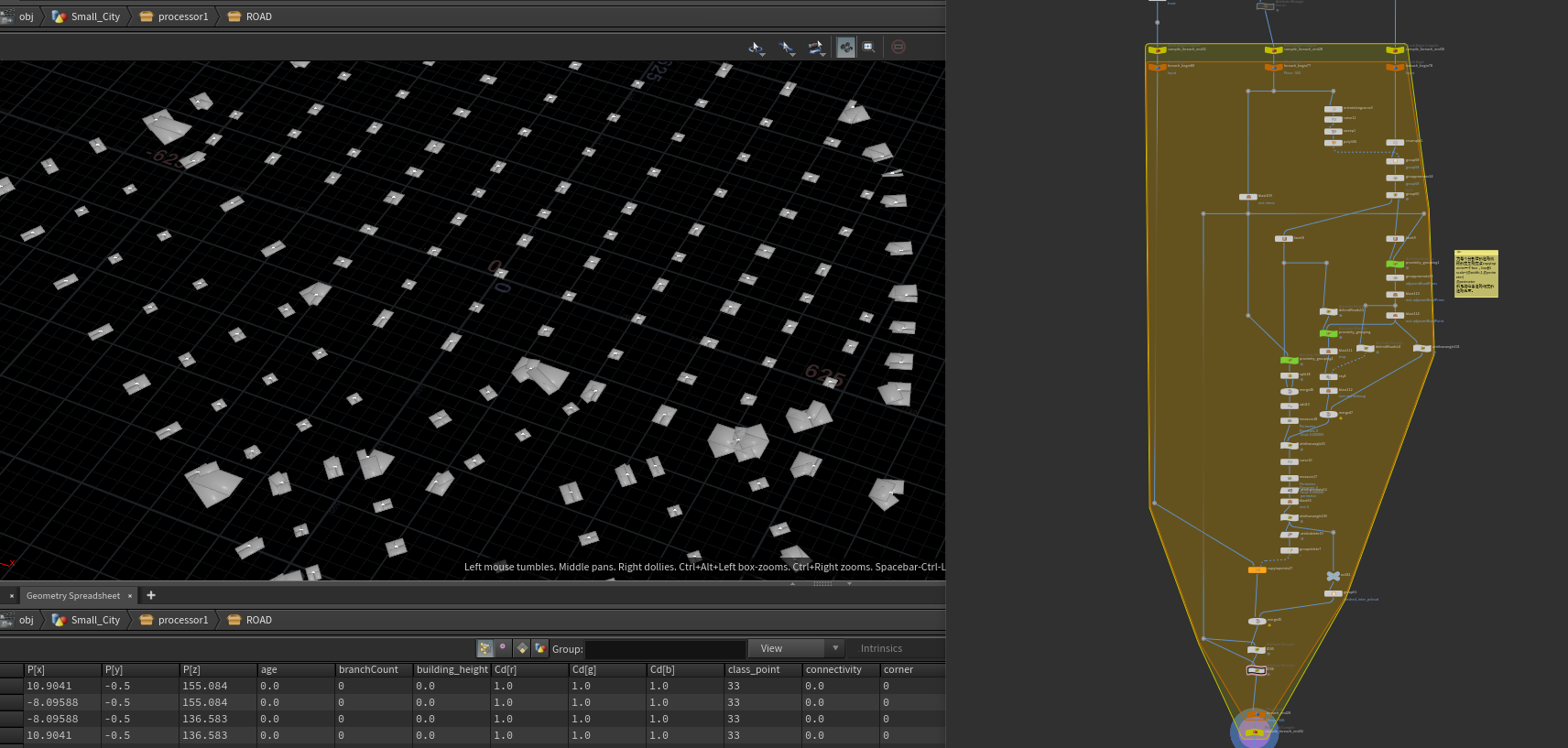
可以看出有些地方的交叉路口没有贴合,我们需要修复一下他们,就是用他们没有相交的地方提取处理做个凸包就能得到 交叉路口修复块模型。

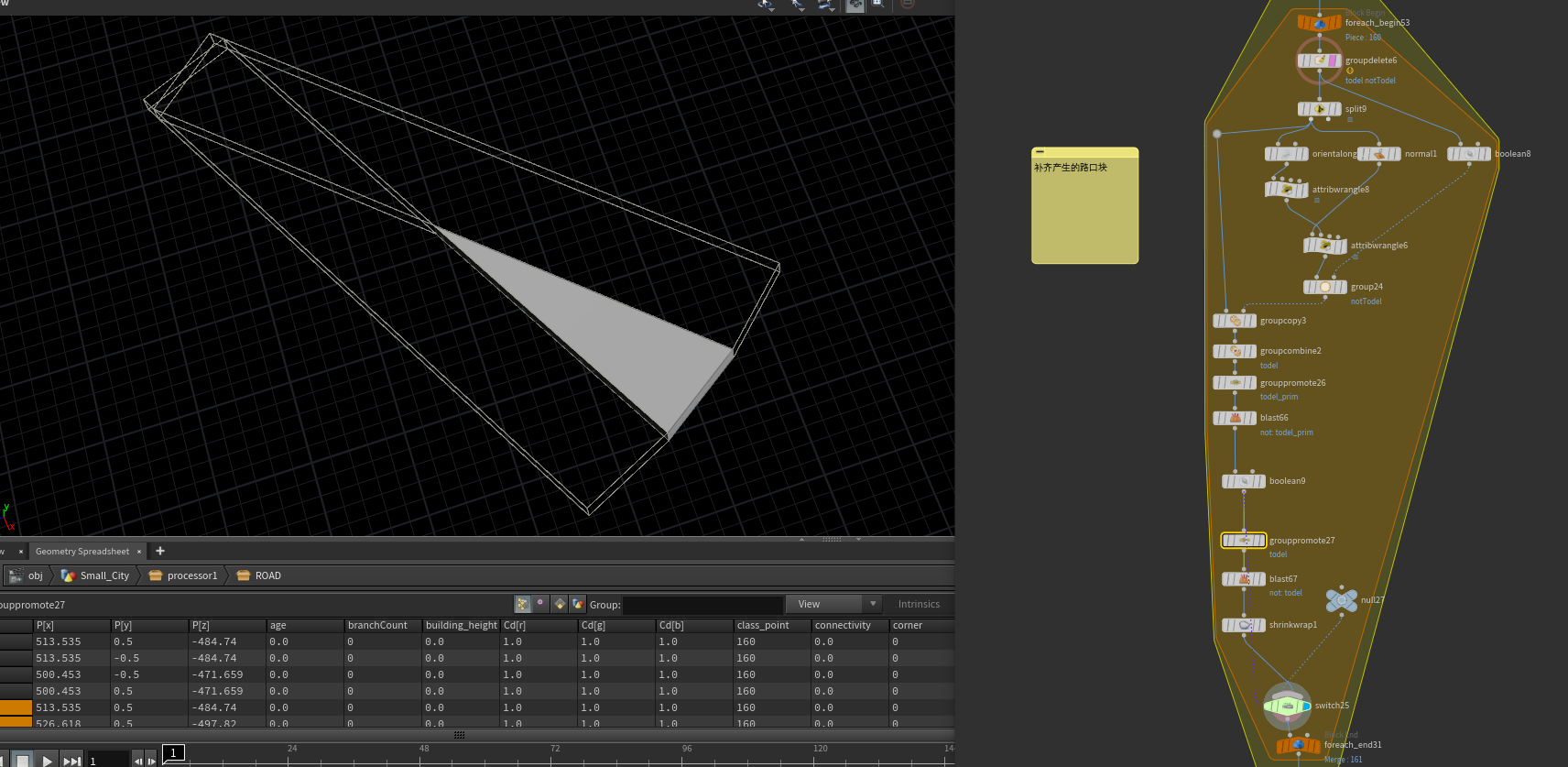
从交叉路口解算器,可以得到两个主要的东西 一个是 交叉路口点云与copy得到的模型(粗模 表范围),两个都有作用 ,先说点云。
点云每一个点在当前位置向法线方向生成一块road长度为@perimeter-3宽度为@width,剩下3m的长度,点云会移动@P += @N*(@perimeter-3);后再生成(3m的宽度主要就是马路口的人行道)。移动前的点云和移动后的点云会合并为新的点云集合。
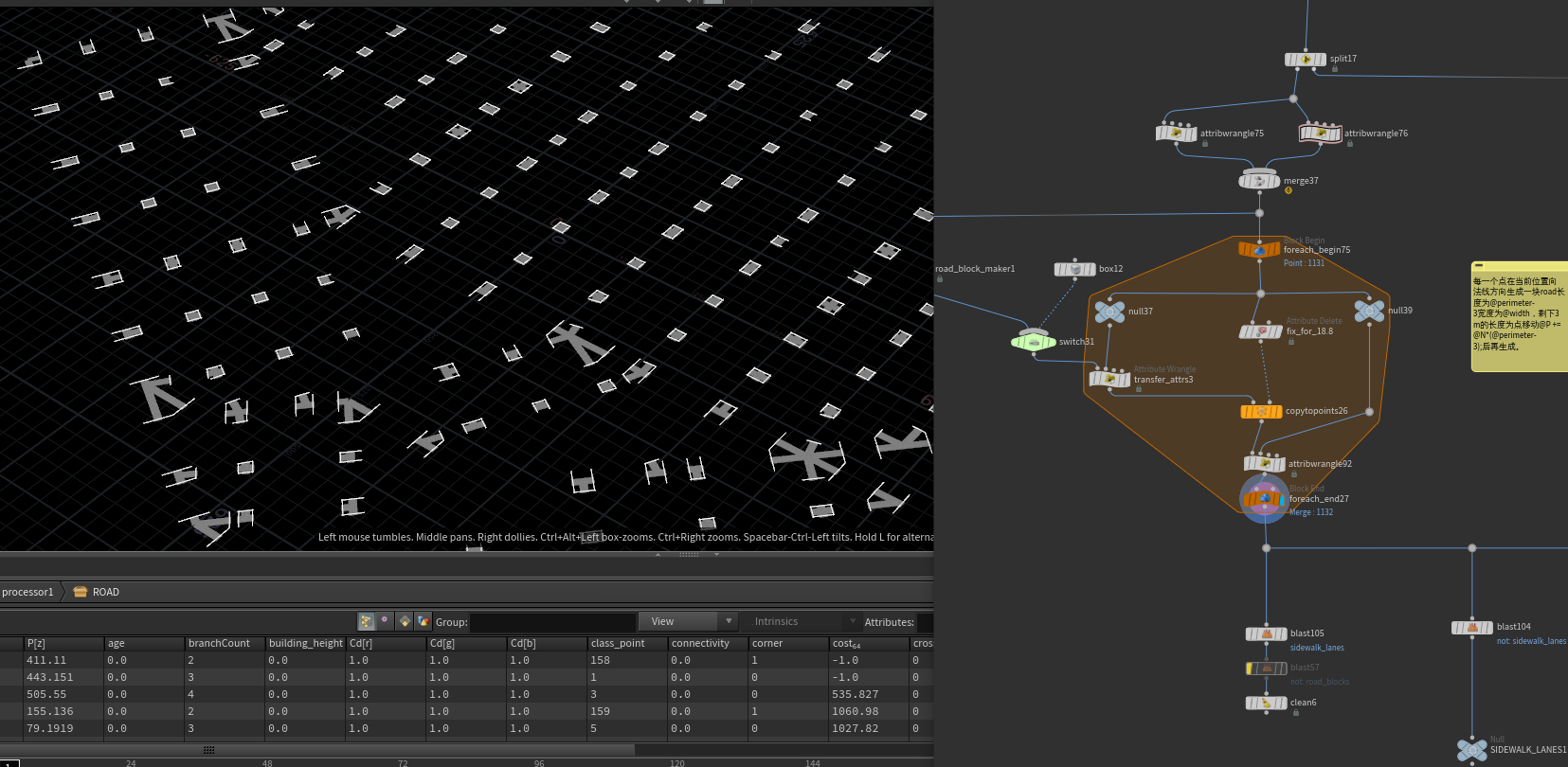
点云copy得到的模型的作用主要就是标记路口的范围,之后就可以专心搞道路的块,道路线段为 整个道路线段 去掉在 交叉路口的块。
拿到道路线段之后分两路,一路是计算道路的各种属性(这就看各自需求啦)
另一路就是主要的生成路这一部分。首先删除太小或者太大的线段,大家法线都向内,然后向法线方向移动5m,判断移动后的法线是否与移动前的法线相同。不同就删除掉当前线段。根据长度分为20m、10m、5m的块大小,太小的用scale的缩放,正常为1,每个块生成一个对应的点云输出。
之后就组合我们得到的数据,拿到道路线段后计算完属性的道路线段点云 、 拿到道路线段后计算得到每一块道路类型与大小的点云 、 交叉路口移动前的点云和移动后的点云会合并为新的点云集合。
组合后的每一个点我们都会附上对应的属性blockCode Type,已经unreal里面路径等等。基本就是结果点云啦
循环每一个blockCode中的第一个点根据附上对应的属性 用road_block_maker产生出对应类型的路模型。
最后给一个可视化输出到input0,可视化就是直接用得到的点云与自己产生的道路模型,做撒点输出可视化(模拟ue里面撒点)
输出0就是可视化 输出1就是点云 输出2车道线与人行道线(车道线和人行道线由道路产生器直接产生) 输出3是路口数据 输出4是产生模型集合 输出5是交叉路口修复块模型
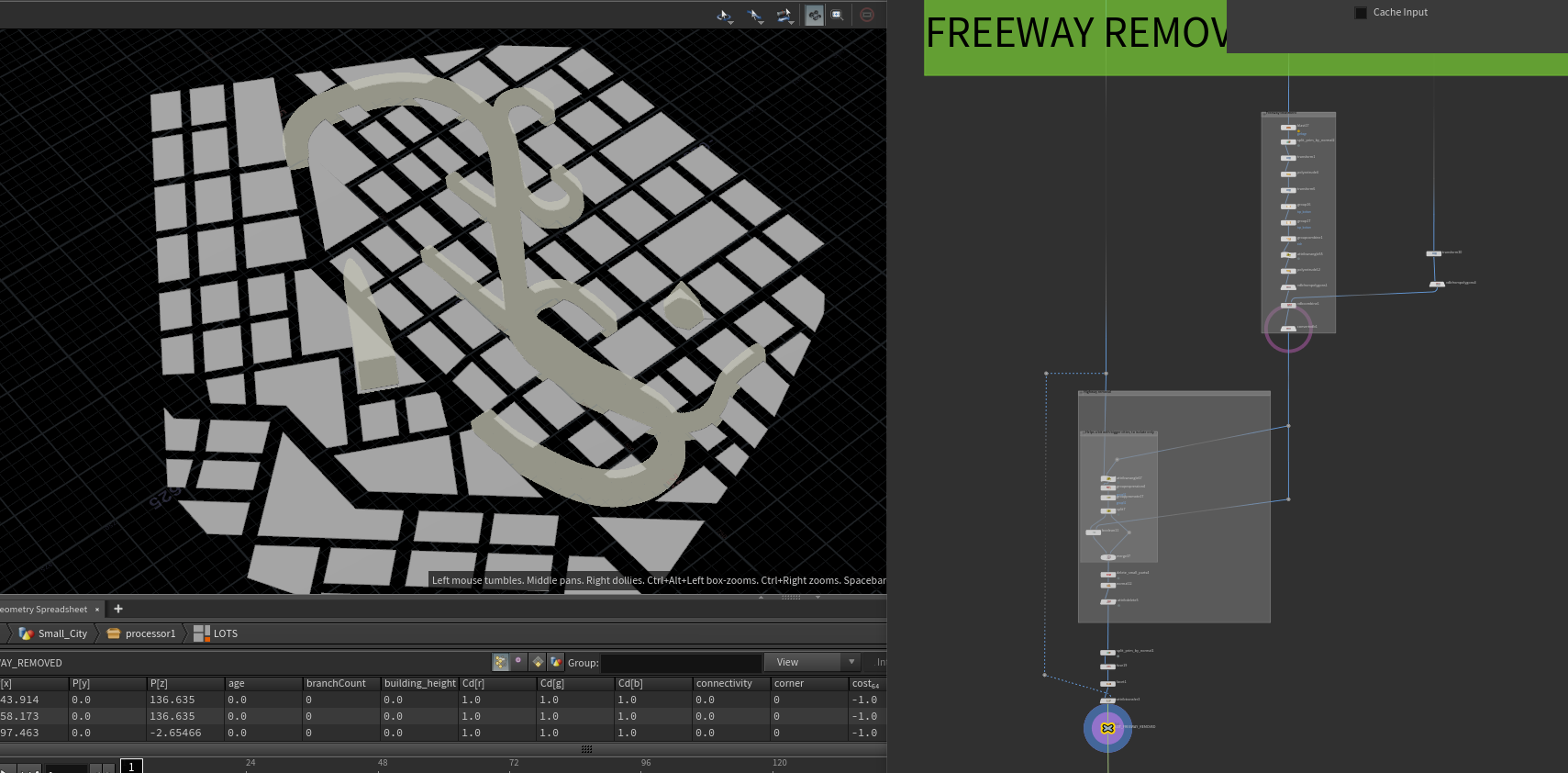
LOTS
LOTS 建筑布局HDA节点的主要输入有4个:
loyout的复合输出中的lots group 、 高速公路 立交桥 、标志性建筑 、HEIGHT OVERRIDE(高度上的艺术指导)
我们会先将高速公路提取处理,取它向上的面挤出一个几何体,将这个几何体体素化之后 Y轴中心为0,与体素化之后的标志性建筑合并转为 阻挡Mesh 后输出,我们再提取出城市布局底座 离 阻挡Mesh 比较近的块,与阻挡Mesh 进行boolean操作,最后未取出部分合并。去除一些比较小的块,并重新整理一下数据。
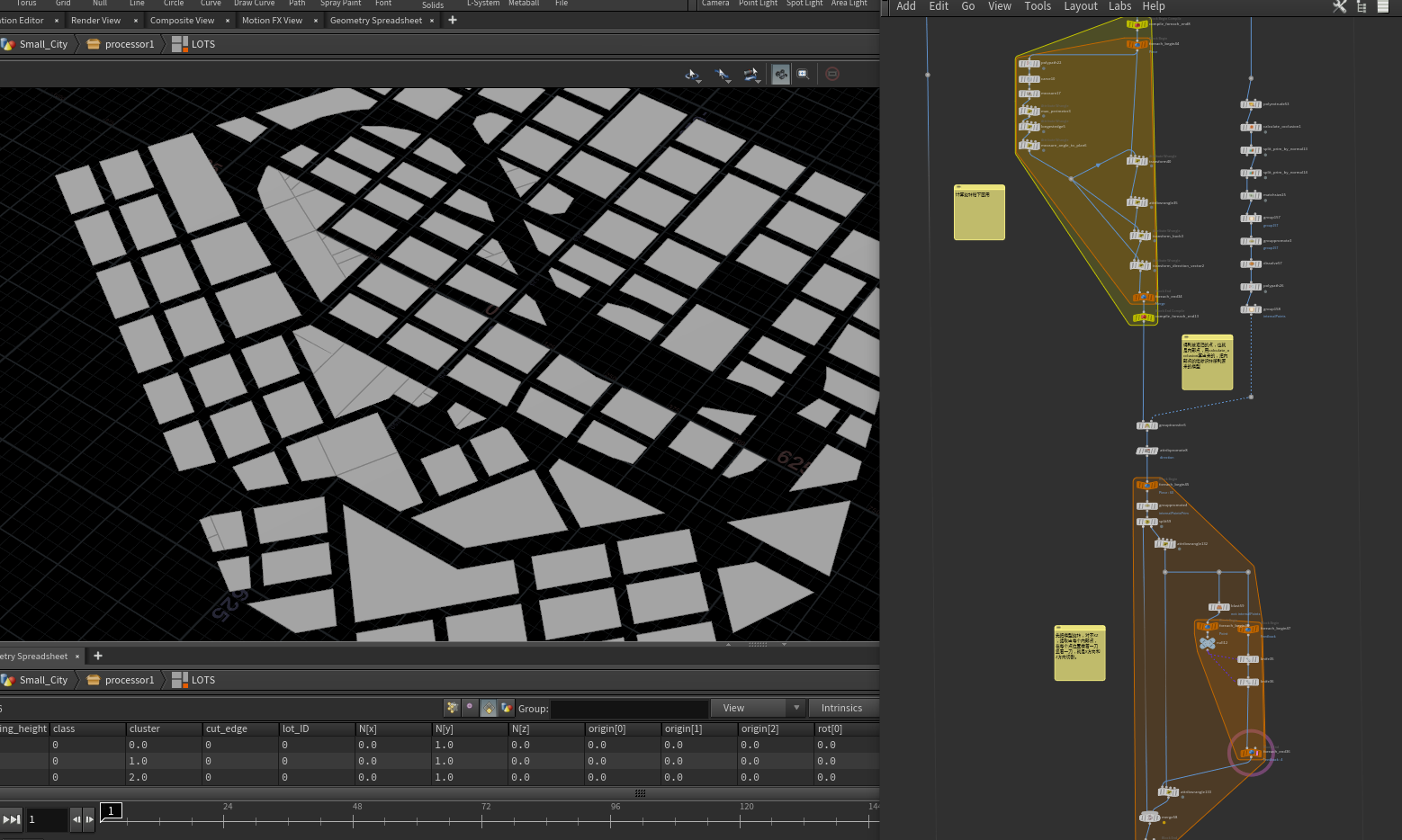
这下基本得到最基础的布局块,接下来有4种布局方式,我介绍3种
1: 就是不布局直接用。。。
2: 45degrees 遍历每个块,先计算得出最长边,再得出最长边与Z轴的角度,将这个块transform到原点并且最长边与Z轴平行,细分当前块,把每个点都判读附近相交两个点到自己的向量角度,如果角度不是 @angle%45 == 0 就标记这个点所在的块,然后删除这个块,完事后在拿到当前线框边,如果哪条边太短了,小于细分的块的长度都给它提取出来。然后在循环遍历提取出的边,如果这个边只有两个点最后出来结果的就两个点,如果边有3个点最后保留距离最远的两个点形成一条新边。
3:subdivison 遍历每个块,先计算得出最长边,再得出最长边与Z轴的角度,将这些属性先存储在这个块上,计算每个块上的每一个点是不是内凹角(两条边构成的角为锐角 ,这个用calculate_occlusion节点快速计算),循环遍历每个块,如果这个块包含内凹角的点,那么我们会先把模型旋转,对齐XZ,提取出每个内凹点,在每个点位置横着一刀竖着一刀,就是X方向和Z方向切割,将切割完的模型输出。如果没有包含内凹点,那么直接输出。
得到切分过后的块之后我们还需要删除比较小的面积,利用周长面积比提取出比较混乱的面,将相邻的混乱面合成一大块在,再利用Lot_subdivision细分,再把分开的拆为一个一个单独的面,再计算周长面积比,再次剔除混乱的面。(lot_subdivision:找到最长边,垂直与最长边切割当前块)
(周长面积比:
多边形的周长与面积的比值,用来度量多边形的紧凑度。圆的周长面积比在所有的几何图形中是最小的。面积是缺陷特征的一个度量。面积只与缺陷的边界有关,而与其内部灰度级的变化无关。缺陷的周长在区别具有简单和复杂形状物体时特别有用。一个形状简单的物体用相对较短的周长来包围它所占有的面积。周长与面积比是用来描述缺陷形状的参数,当形状为圆时,周长与面积比最小,越呈长条状,周长与面积比越大)
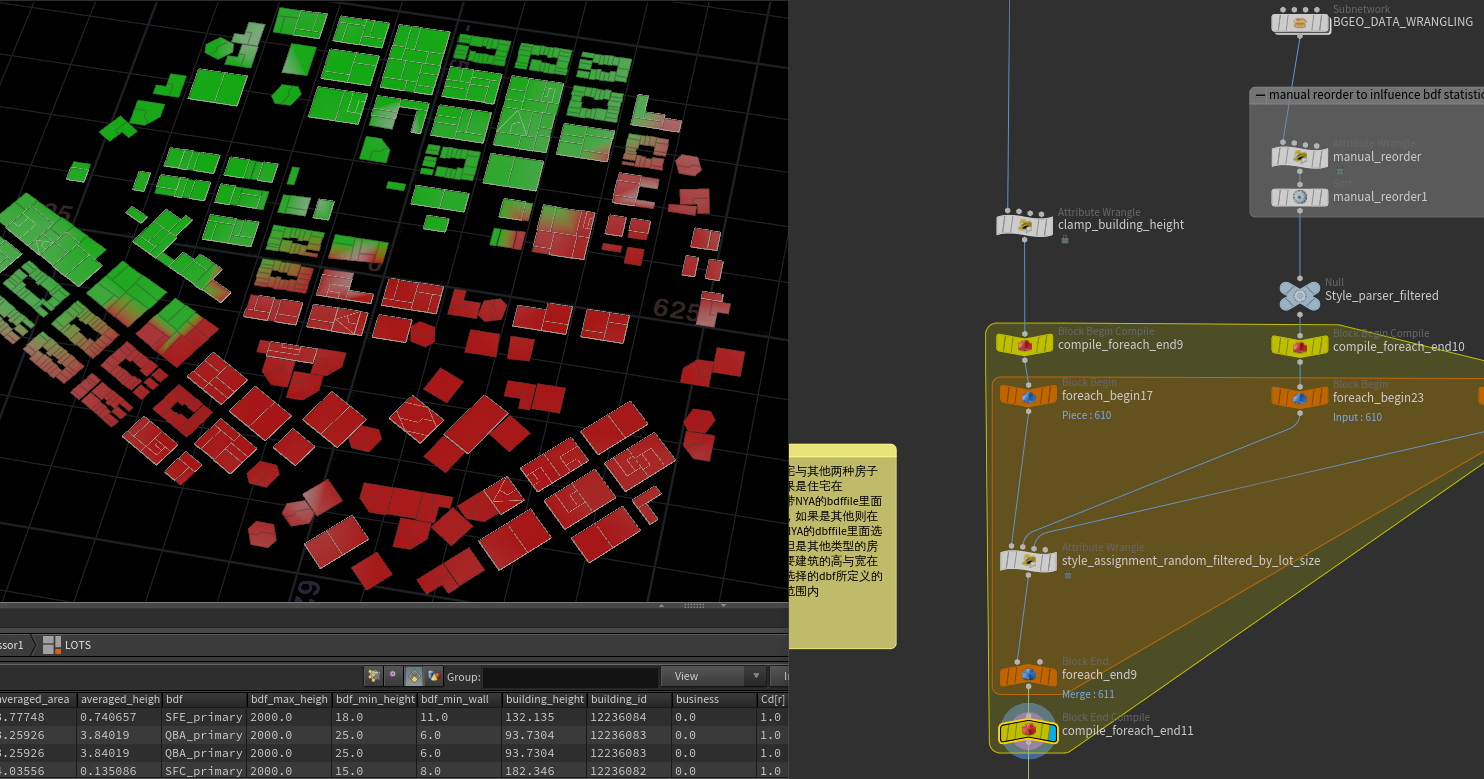
布局拿到之后我们可以将loyout的复合输出中的city_metadata上的城市高度数据转递到新的布局块上。
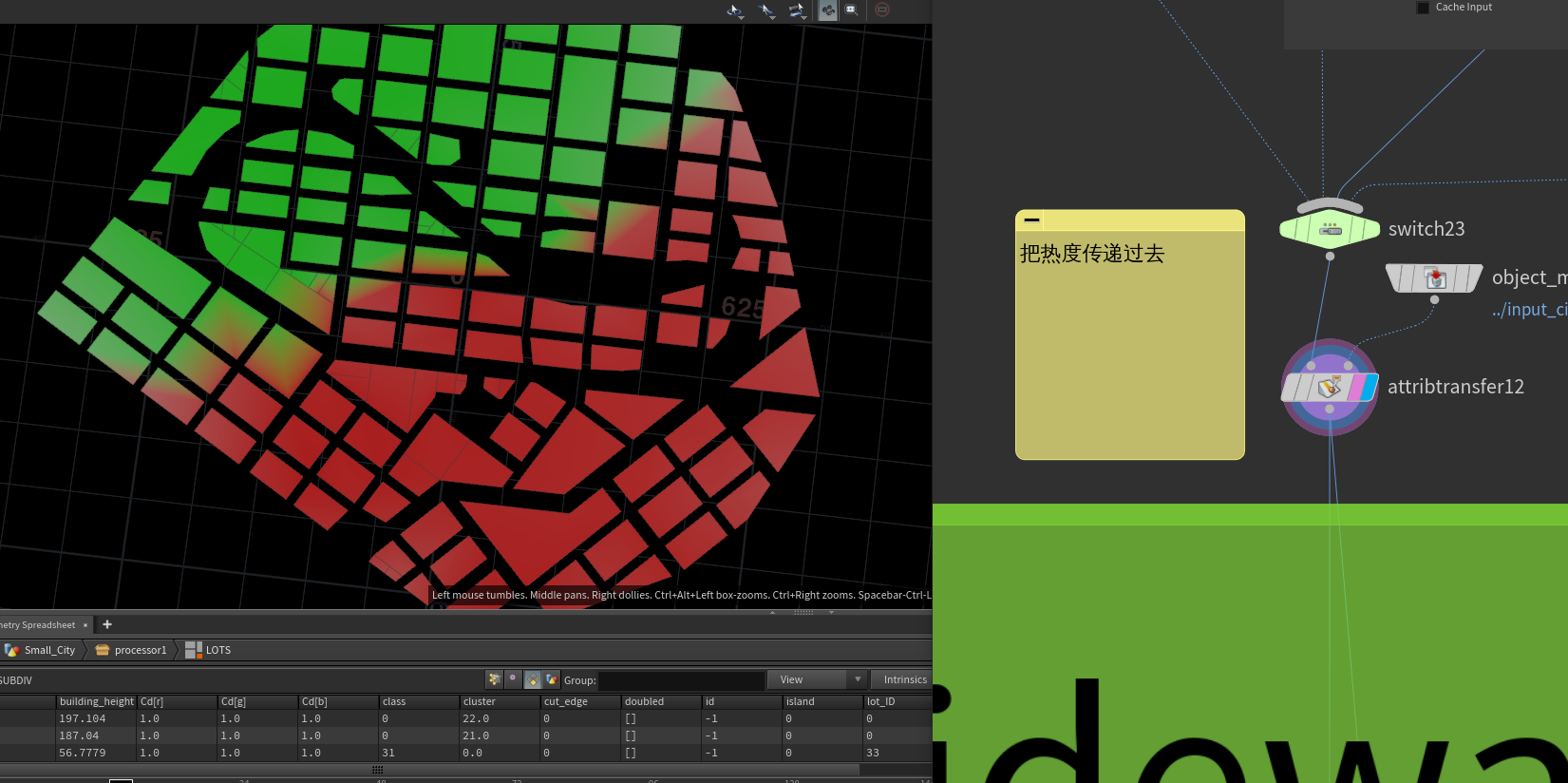
之后找到沿着街边的布局块,我们将这些块根据对应道路类型人行道宽度做出对应的收缩,主要是A道路与B道路 C道路的人行道是默认宽度,将道路与人行道生成出来与对应街边的块做一个boolean操作。
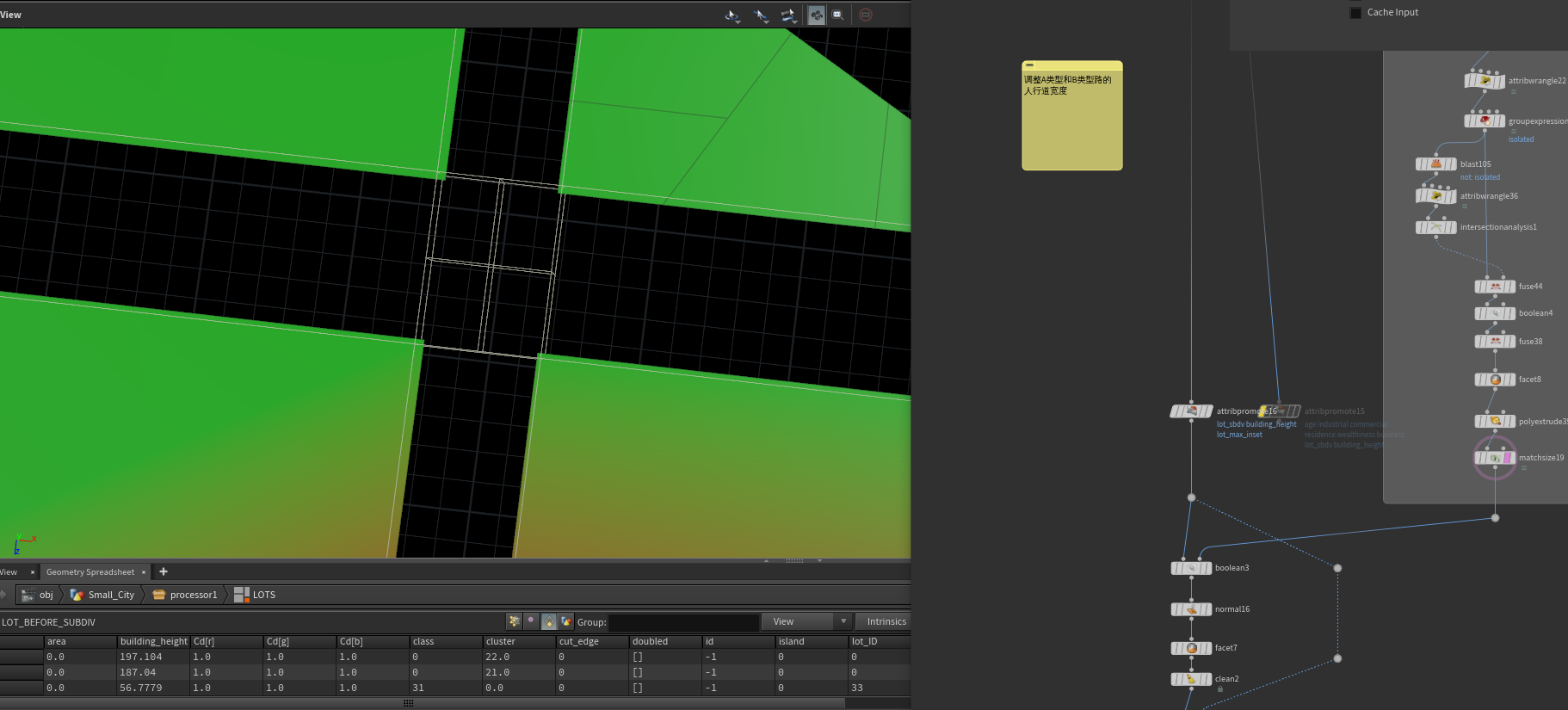
将boolean之后的块整理过后,与输入HEIGHT OVERRIDE 做一个高度映射,就是如果当前建筑高度小于HEIGHT OVERRIDE的高度,那么当前建筑高度就等于HEIGHT OVERRIDE的高度。
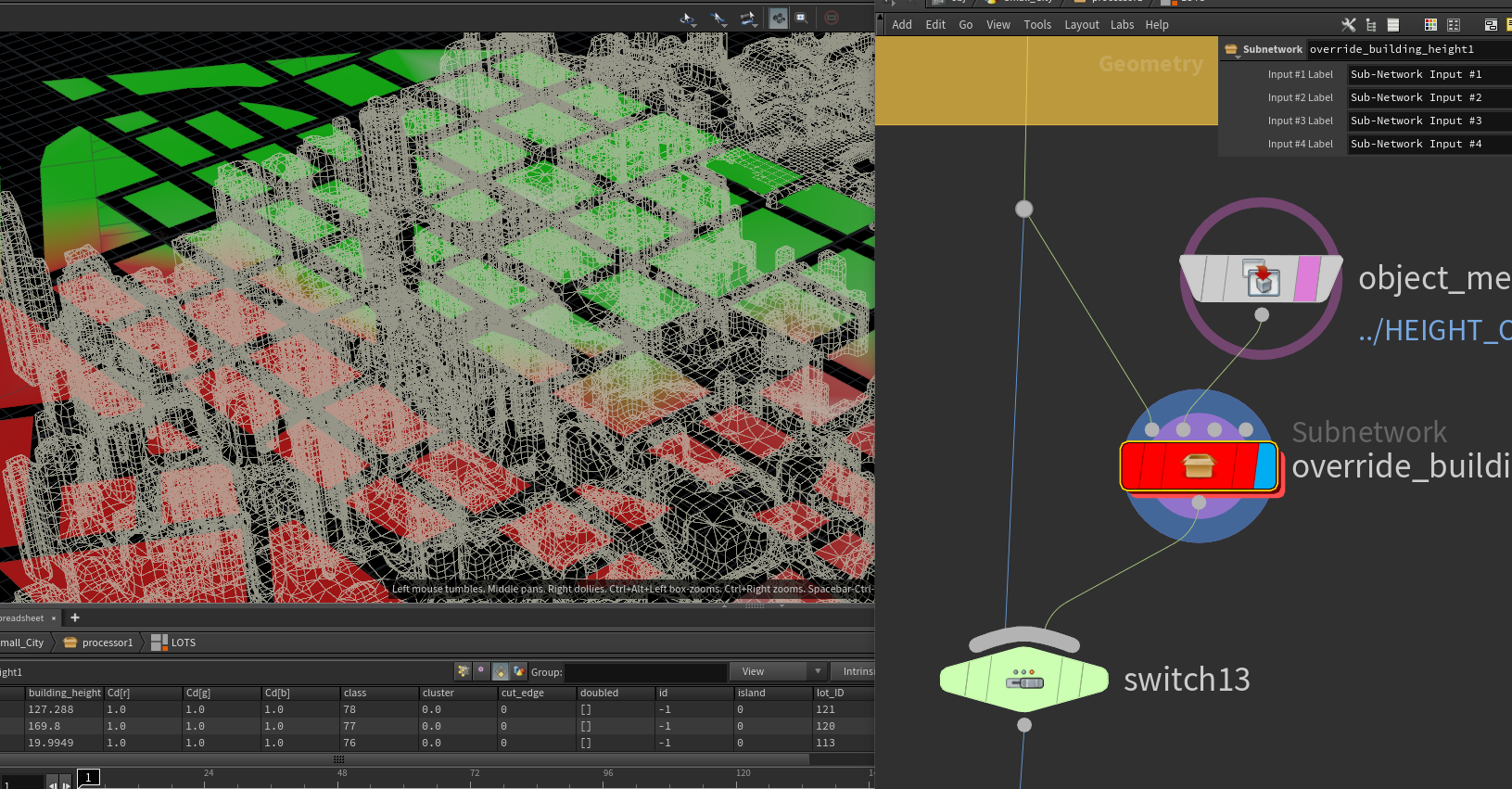
之后便是给上布局块不同的建筑风格,这里有两种,一种纽约风格,一种传统风格。
剔除不是正方形的面,判断条件1: 等于四个点,条件2: 角度余90为0.
之后再根据建筑高度(一开始拉的那两个凸的包代表建筑的高度)高度小于一定值,
之后再剔除太小的 与 太大的块,剩下的就用纽约风格来布局
被剔除的都再一起用传统方式来布局
纽约风格:
先找最长边,最长边与相邻边平行 x 和 z轴的角度值,旋转到与X轴与Z轴平行,
头尾各隔25米切一刀,split出来头尾的25米的条,再x轴细分为10米一格10米一格,格子的大小3米内随机浮动。
split出来的中间的条,再按照头尾25米切一刀再同样split出来头尾的25米的条,再x轴细分为10米一格10米一格,格子的大小3米内随机浮动。
找到比较小的块面积小于220大小,提取1/7合并为大块,
再把中间的边(内边),向内方向随机offset3米大小
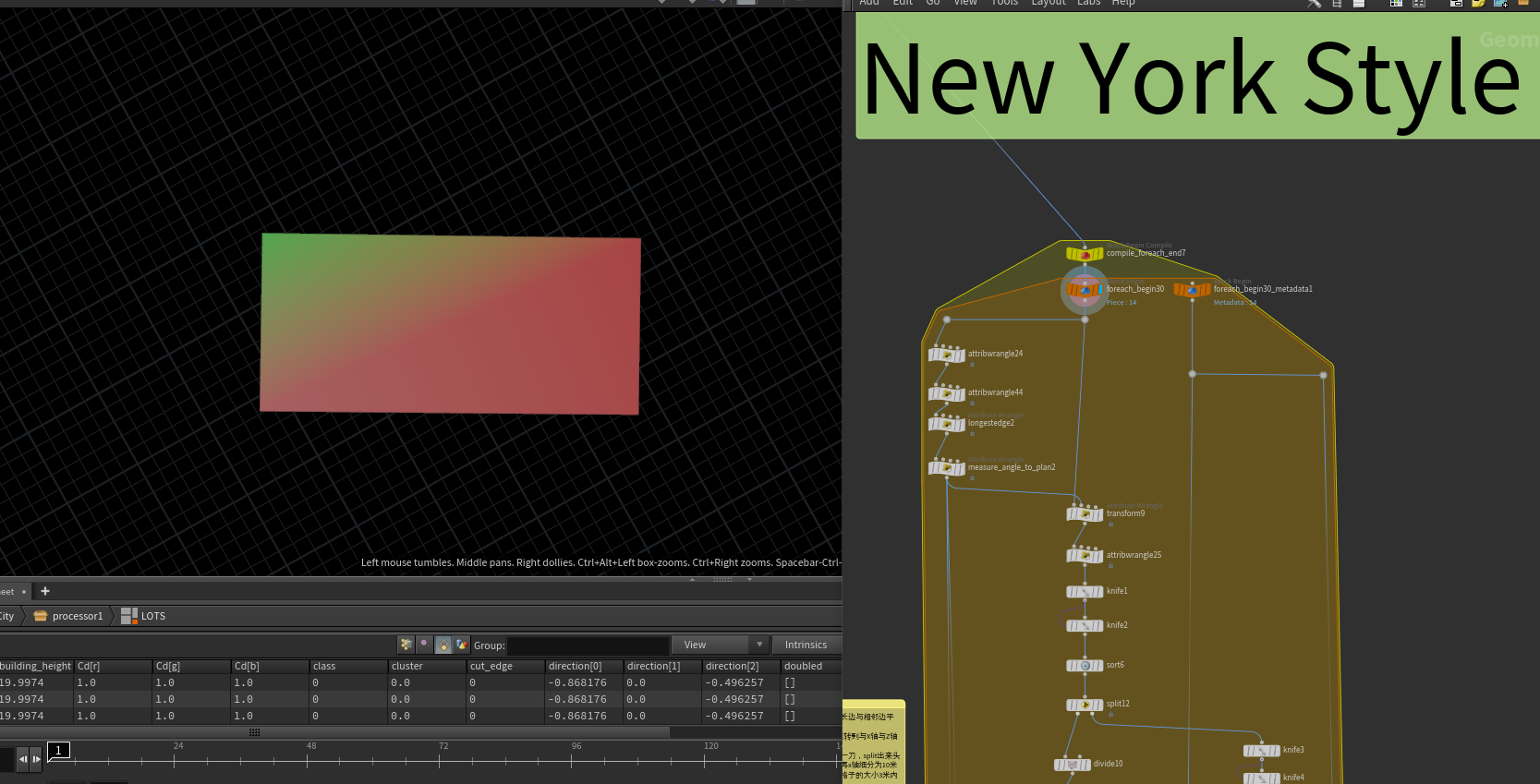
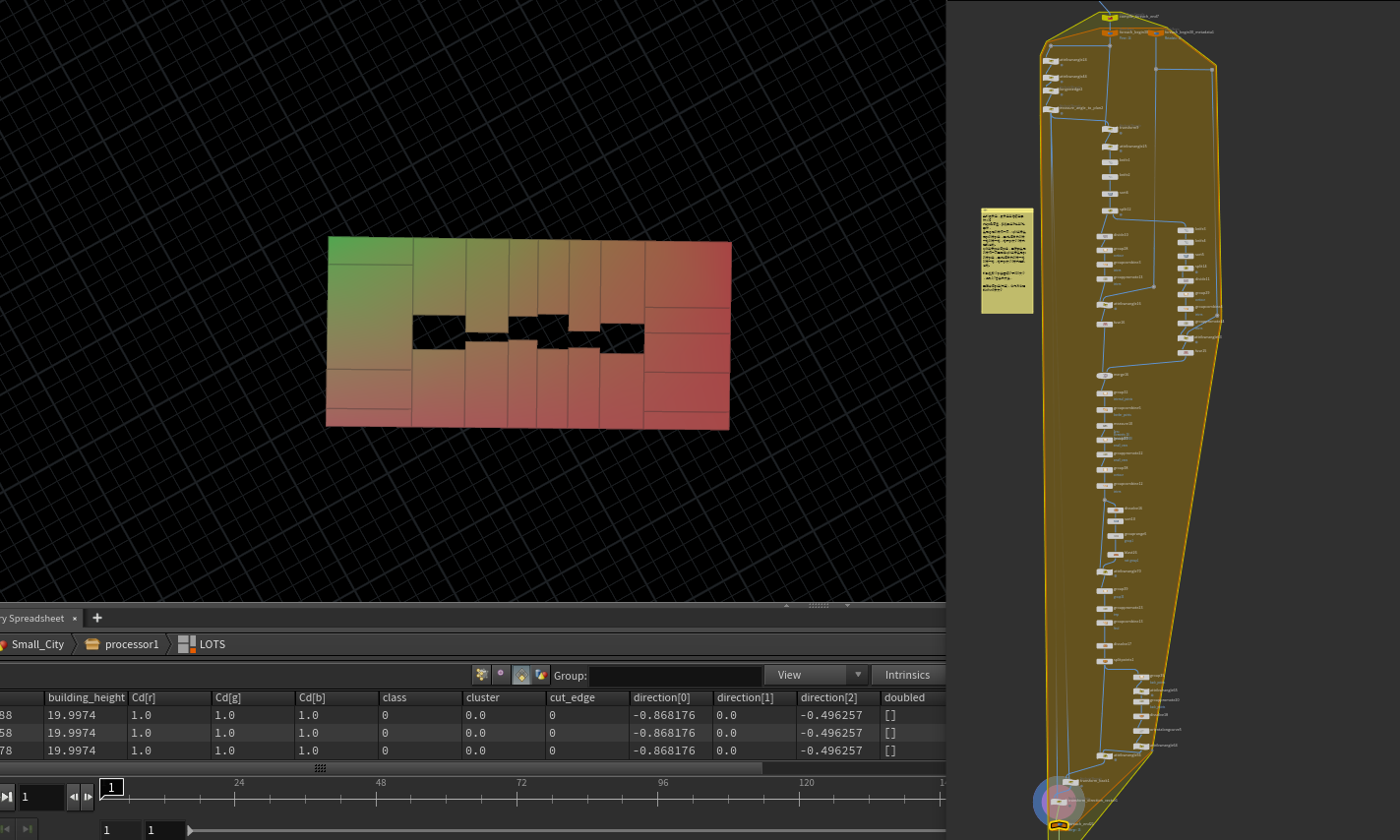
传统风格:
通过 面片的面积与建筑高度来决定lot_subdivision的切割迭代次数,最后如果面积还是大于某个值我们还需要再切割一次。
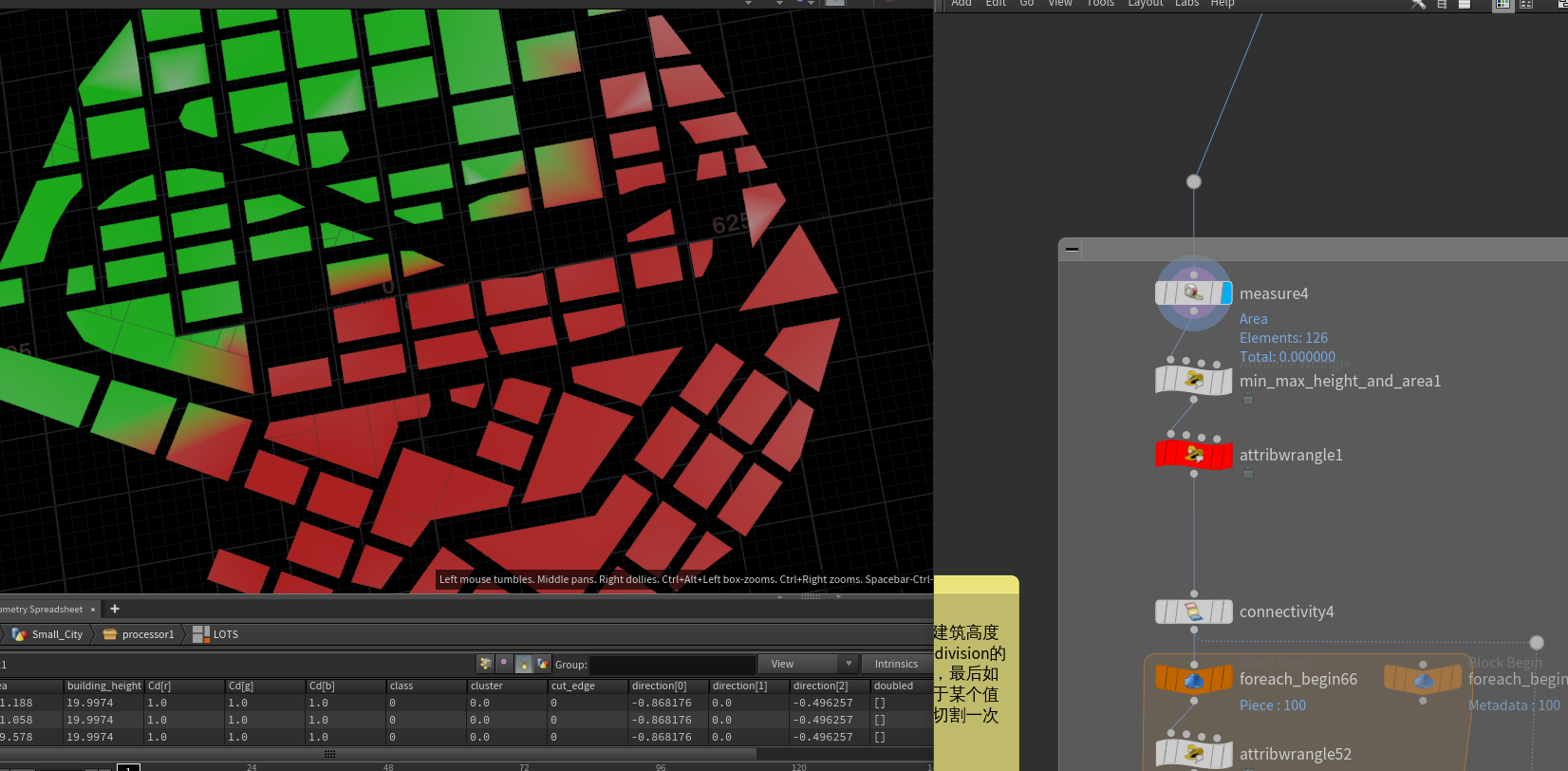
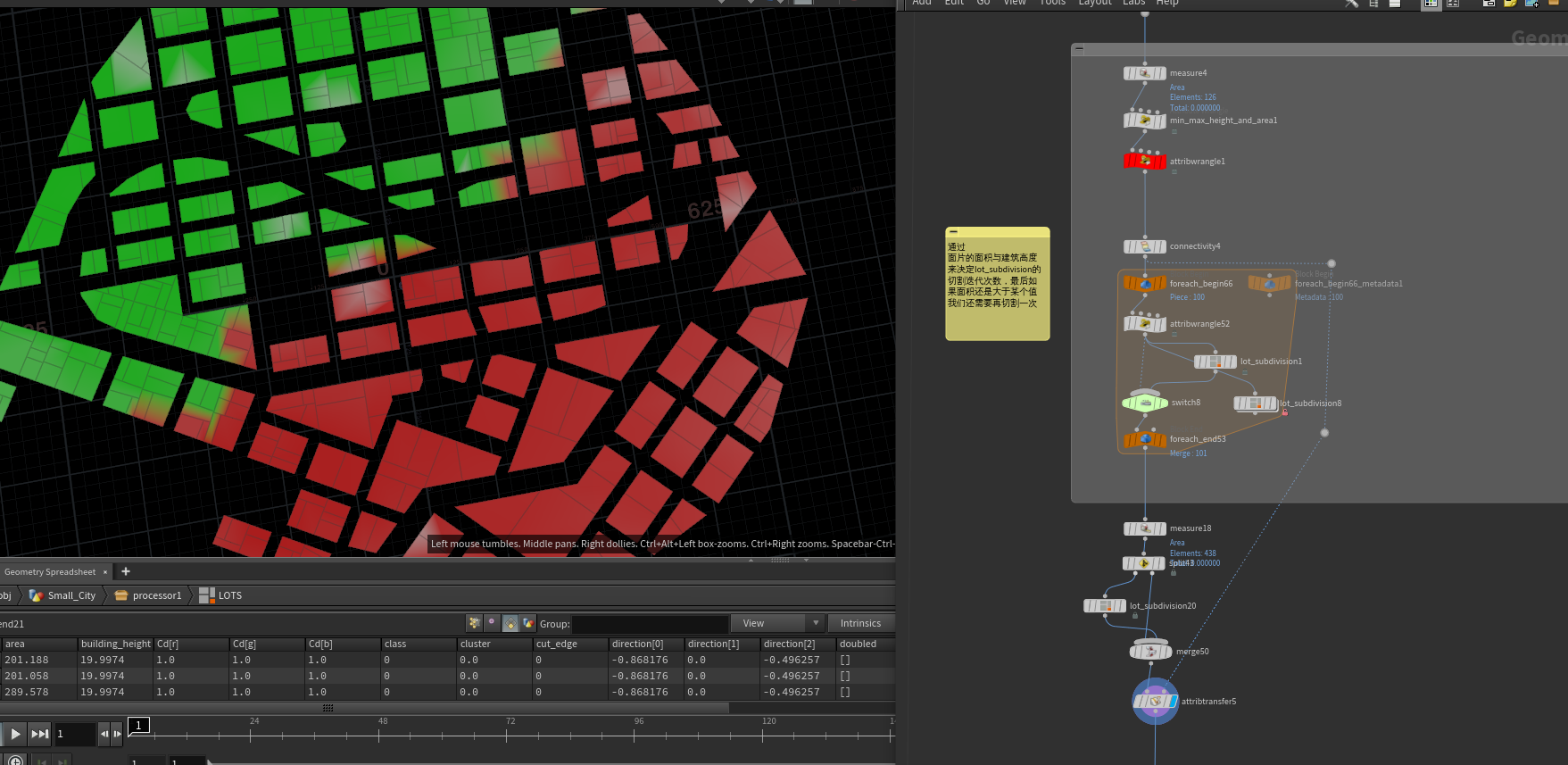
将两种风格的切割完的块合并输出,做一些数据处理,剔除比较小的块、找到内部块(没有一个边接触空地)等数据操作。
现在有些小块的形状还是太过不规则,我们将分离出不是4个点构成的块。使用提取做好的17中块用UV填充的方式布局在这些不规则的块中,合并4个点的块输出,
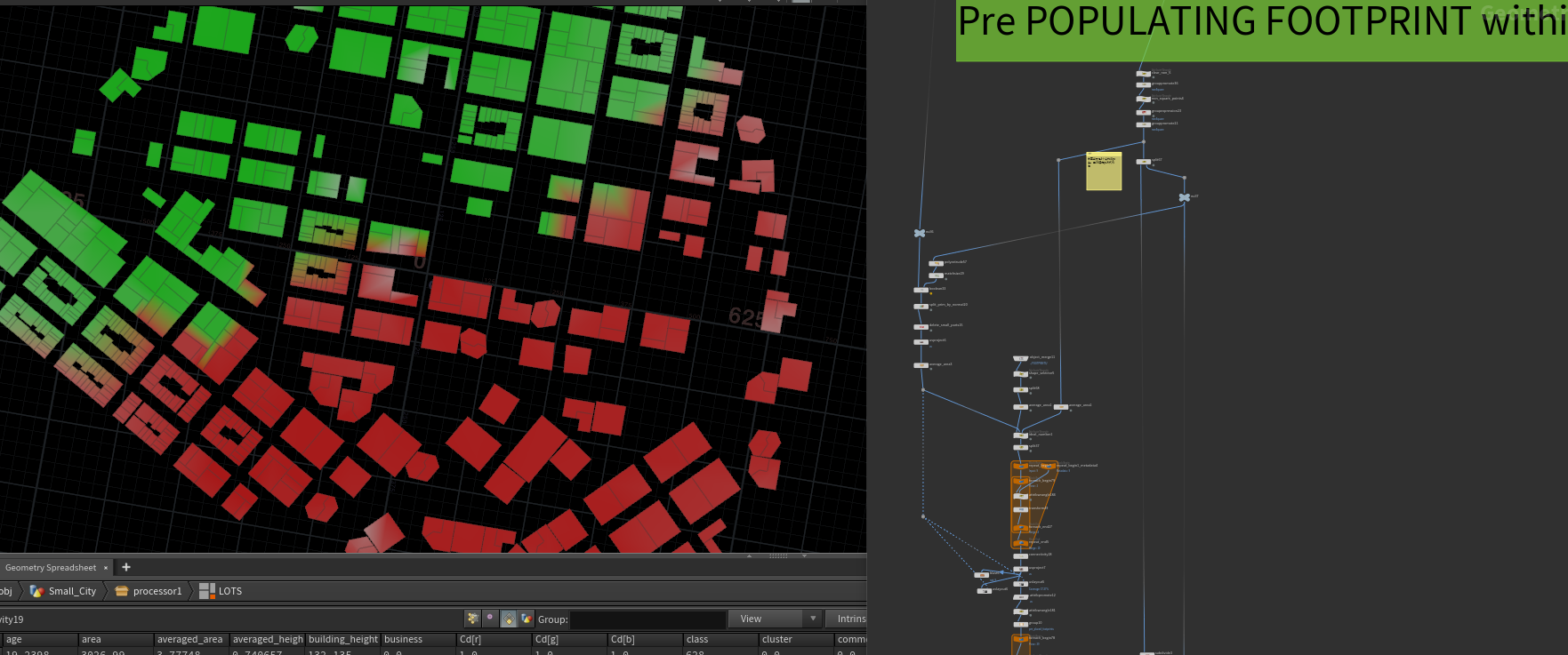
我们又要分离出沿着街边的布局块,垂直与道路的法线做一个随机的offset。让街边有些不规则的感觉。
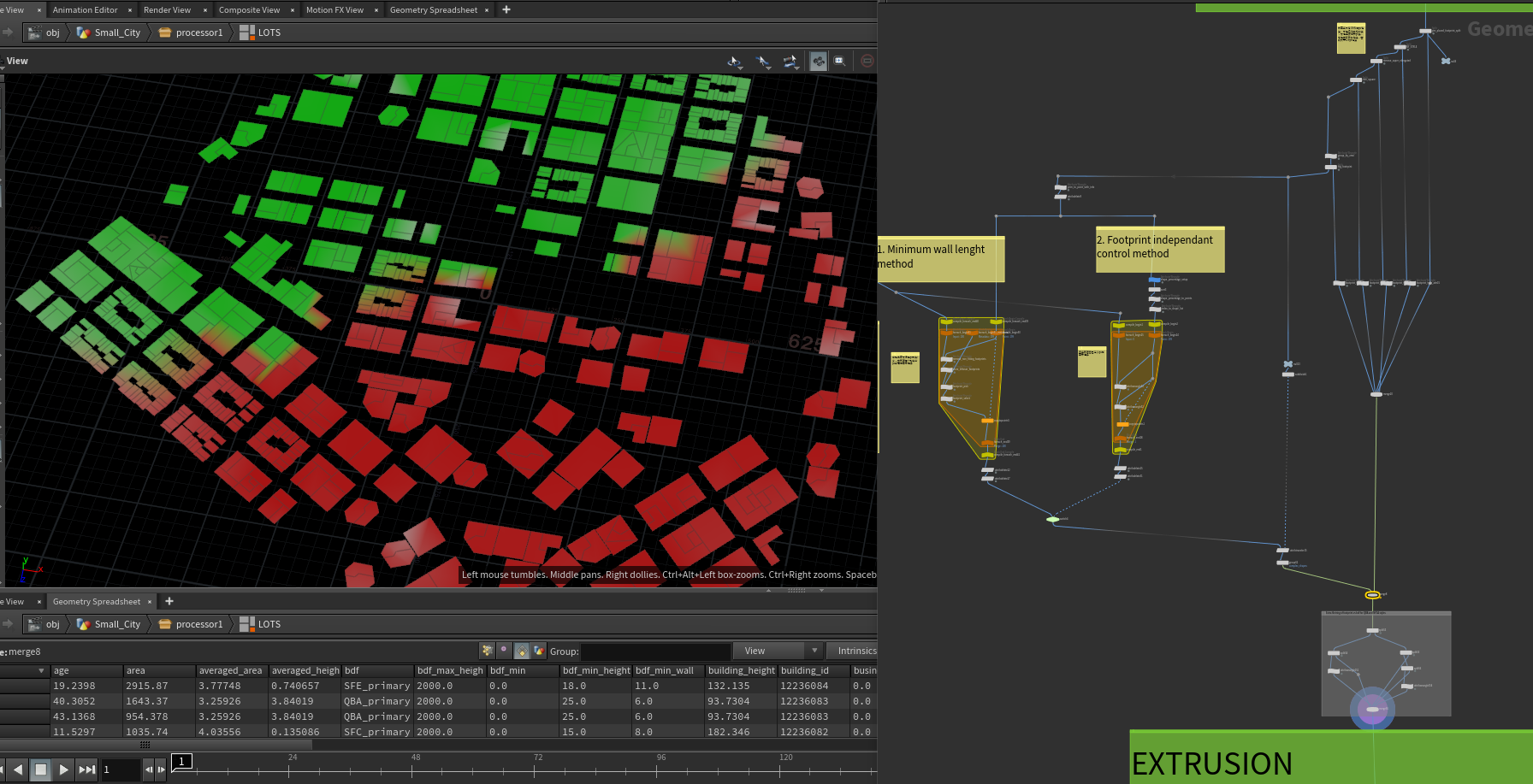
用现在的块做一次与输入HEIGHT OVERRIDE 做一个高度映射。然后在做一次数据的清理,包括剔除一些比较狭长的块等。
之后我们需要引入 BDF 文件数据,我们将bdf信息赋予到每一个地块上,地块根据城市元数据分住宅与其他两种房子,如果是住宅在 属性带NYA的bdffile里面选择,如果是其他则在不带NYA的dbffile里面选择,但是其他类型的房子需要建筑的高与宽在当前选择的dbf所定义的高宽范围内,
得到带有BDF信息的地块后,分离出没有UV布局的地块,不是纽约风格的块,不是超级细长的块,不是正方形的地块,面积大于629的地块,这些地块我们将赋予它们我们制作的预制形状。
有两种选择方法 一种是 根据BDF的最小宽度信息移除宽度不满足的预制片,在根据每个预制片的出现概率来选择,另一种是 直接根据自己定义的概率来选择。选择完之后与我们分离出的块合并输出。
拿到最终的地块之后,我们会分两大类五种方式
一类是帝国大厦类型的和传统类型
帝国大厦类型区分是根据只能特定预制地块类型,地块面积不能太细长,不能太小,按照比例与预制地块类型分配两种不同方式的建筑, 其他为传统类型 。
帝国大厦的两种方式分别为 1 类型大厦是挤出一个楼体基础,再在楼体顶部挤出为一个锥体,体素化,在体素内撒均匀点,每个点copy一个正方体,再把超出体素的正方体删除既可
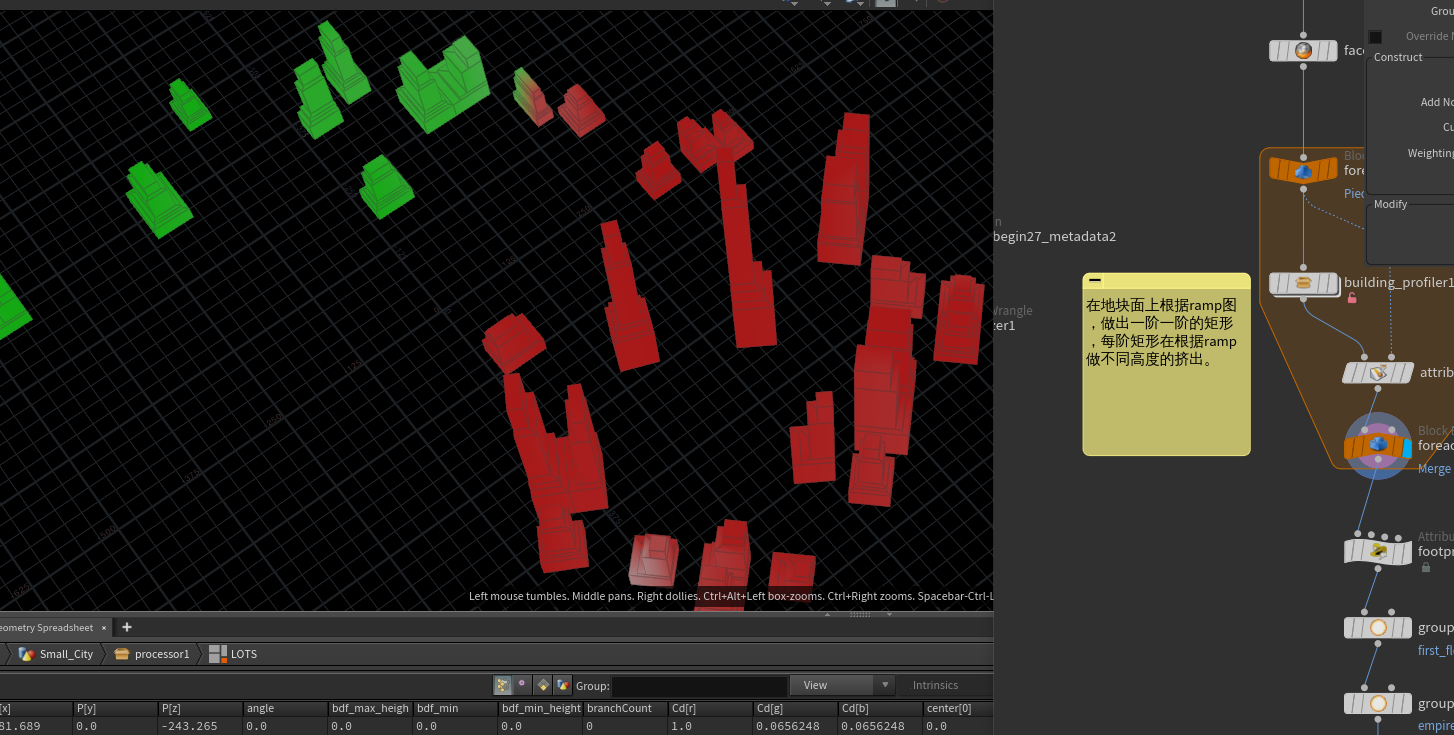
2类型是在地块面上根据ramp图,做出一阶一阶的矩形,每阶矩形在根据ramp做不同高度的挤出。
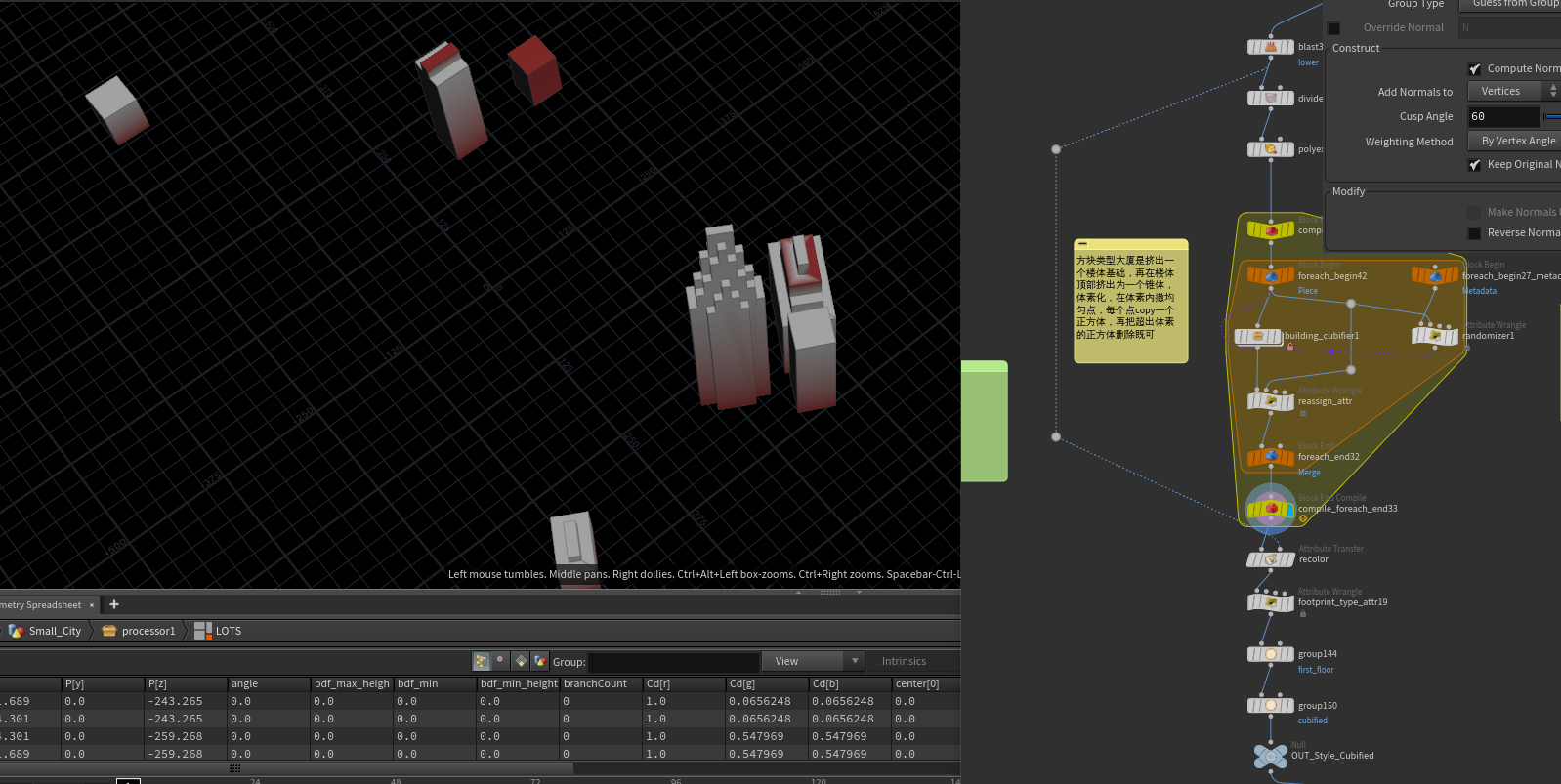
传统类型 3种分别是 一级挤出 、二级挤出 、三级挤出
一级与 二级、三级的区别在与是否为复杂形状,就是一开始不是4个点构成矩形 用uv布局的地块
二级与三级的区别在与自己分配的比例参数。
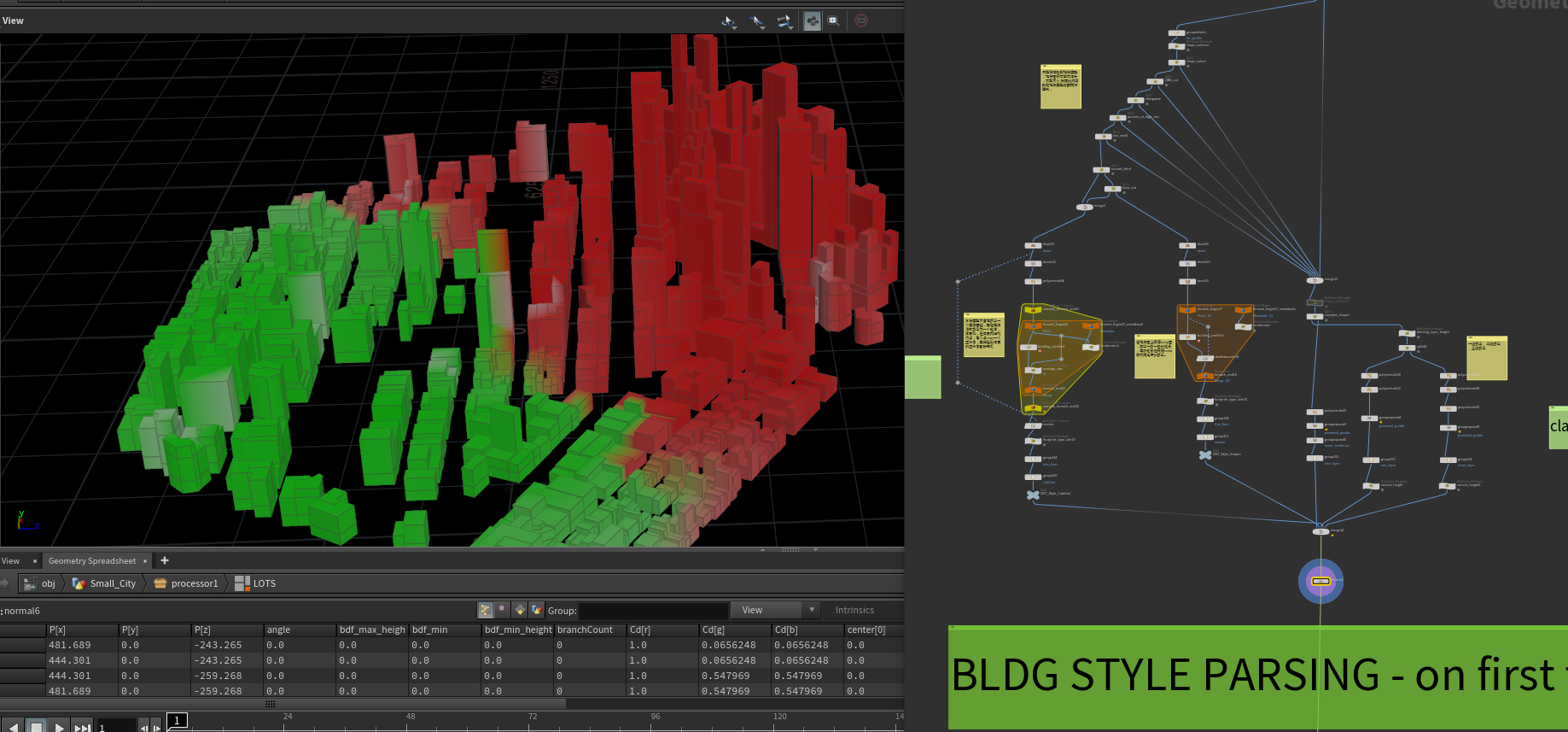
这样基本就得到了最基本的BDF建筑体,如果我们需要那种下层是一种BDF类型,上层是另一种BDF类型,我们需要把一些BDF的最底层就是第一级的挤出剔除出来,换一种新的建筑风格就可以。
然后我们就要判断建筑的正面和背面,主要是细分后用法线打射线到包围盒上,打中为正,自己@P+(v@N*0.001)打自己,打中为背面。得到的正面背面数据再传递回BDF建筑上。之后就是为BDF建筑计算一些之后要用的属性,根据BDF类型给上不同颜色即可输出。
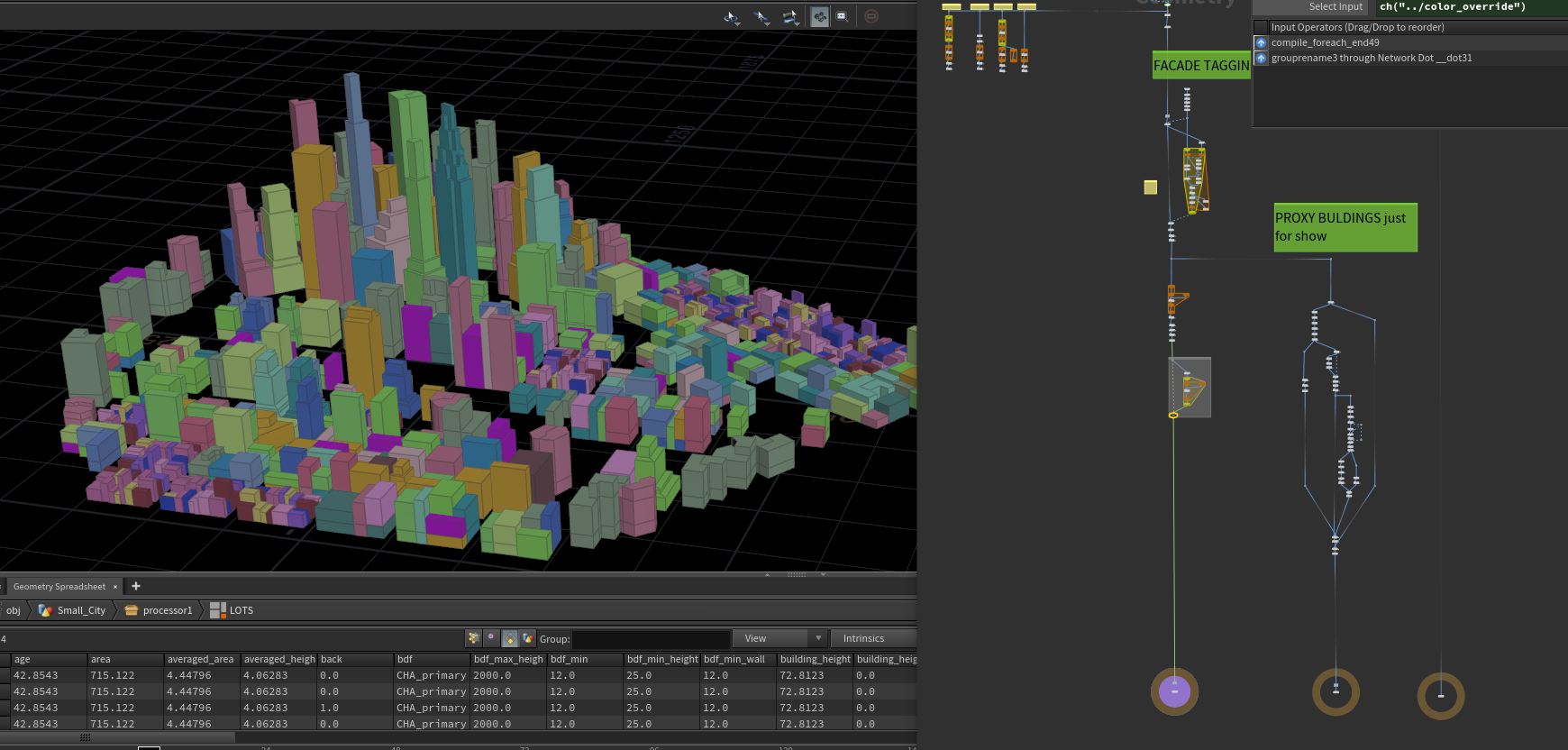
building_generator
building_generator这部分算是最多,也是最重要的一部分,因为内容比较多,这次主要讲关键部分。
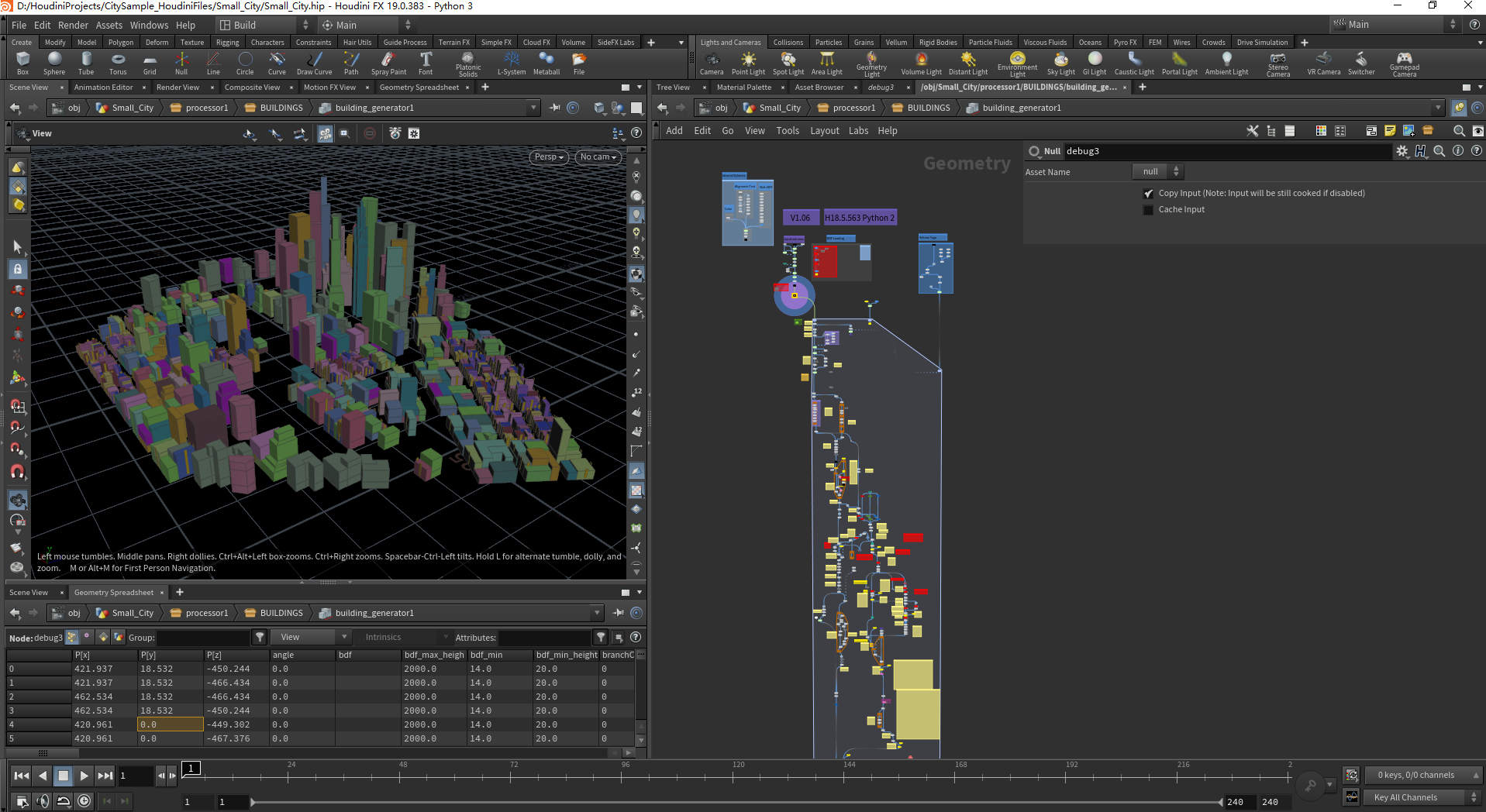
首先进入building_generator这个HDA,一开始这部分是参数选择出来,我们可以直接到debug3这个节点,重点逻辑就是我们下面的循环。
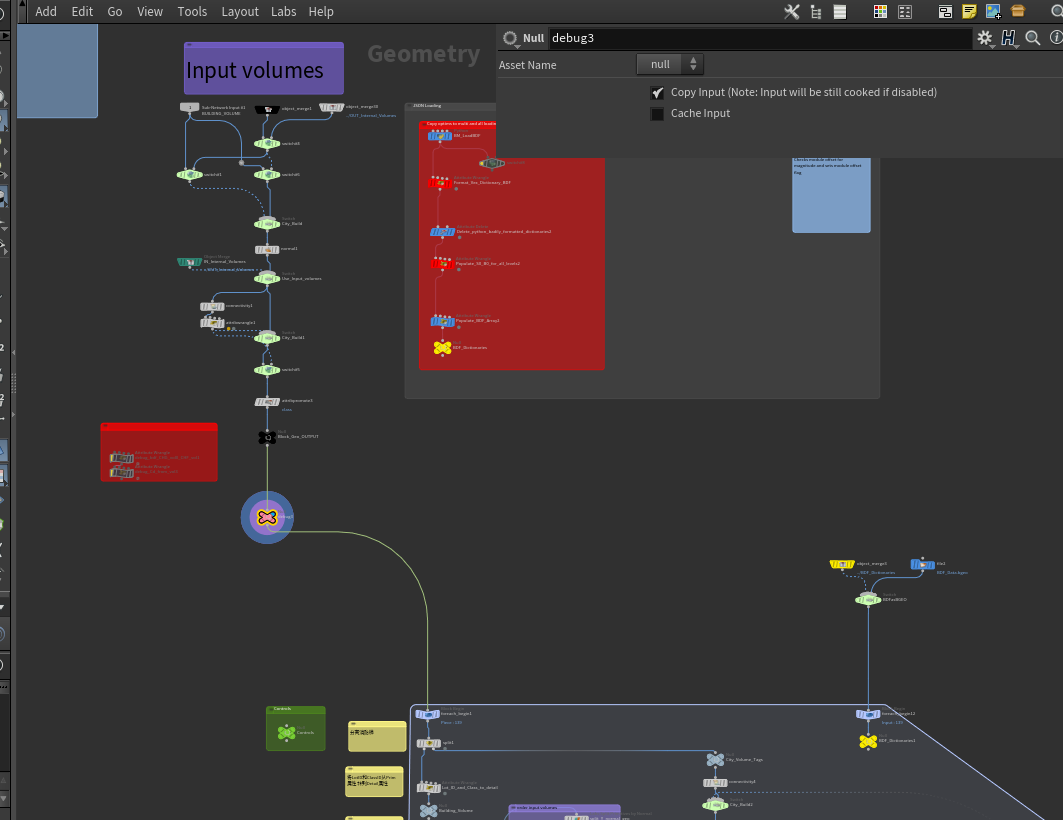
进入之后,我们选择某次循环来分析其中逻辑,首先得到我们单个建筑之后,我们需要分离出建筑的附加消防梯,将建筑本身独立出来,将建筑上的LotID和ClassID从Prim属性 转到Detail属性,将自身的BoundMin和BondMax记录到detail属性,选择是否需要从Volume中提前UV和是否从Volume中得到颜色,这里我们可以直接不用。
选择是否从Volume中提取BDF,这里我们选择为是,我们将Prim的bdf路径提取出来放到detail上,对single bdf 与 mulit bdf做差异化处理,在生成LOTS时建筑BDF是有单层与多层的区分,一个Volume(vol)就是一层,多层最多支持3层。然后记录每个prim所在的vol。
这里有个有意思的点,这里作者用了硬编码去取一个josn,而且看作者的文件命名感觉作者以前是寒霜的人。
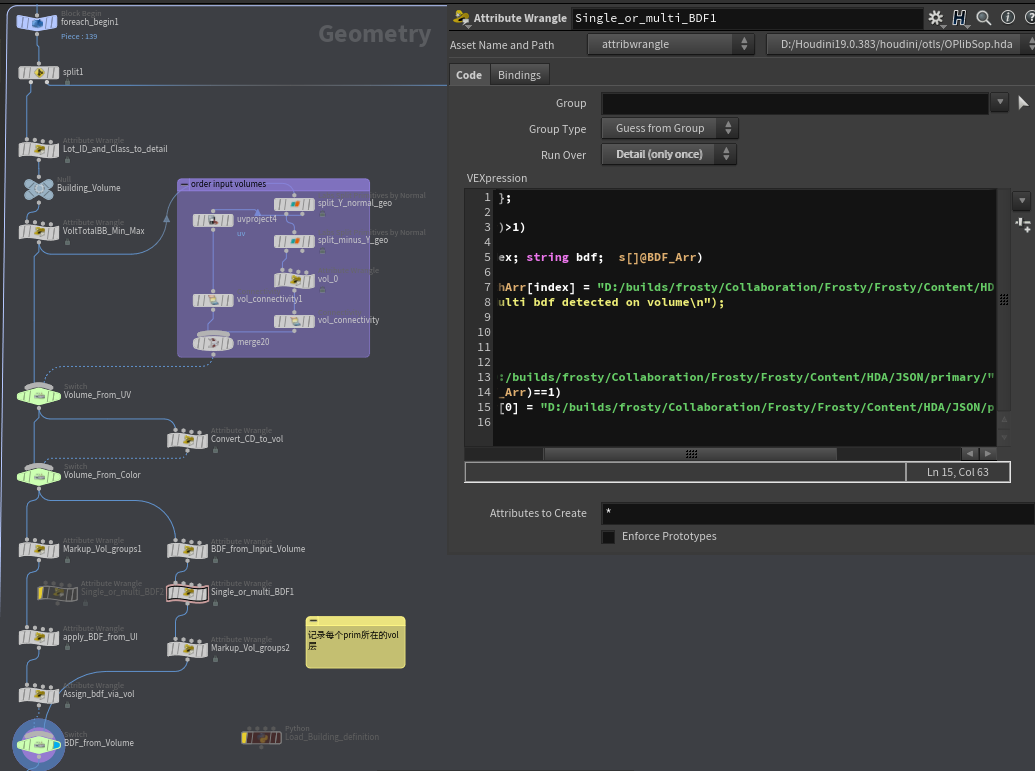
做完bdf相关预处理之后,我们还得清理一下volme模型,我们将vol的数量存储在detail,再通过法线找到面向Y轴的模型,将模型分为两部分处理。
之后也会这样。法线向上的面我们称为顶面,反之称为侧面或者墙面。
顶面的处理操作为清除顶面内部点。
侧面的处理操作为清除面内部的线。
处理完之后将两者Merge起来即可。
预先将我们的BDF属性处理一下,分为一个bdf_full 和 dbf,就是一个为简称,一个为全称。
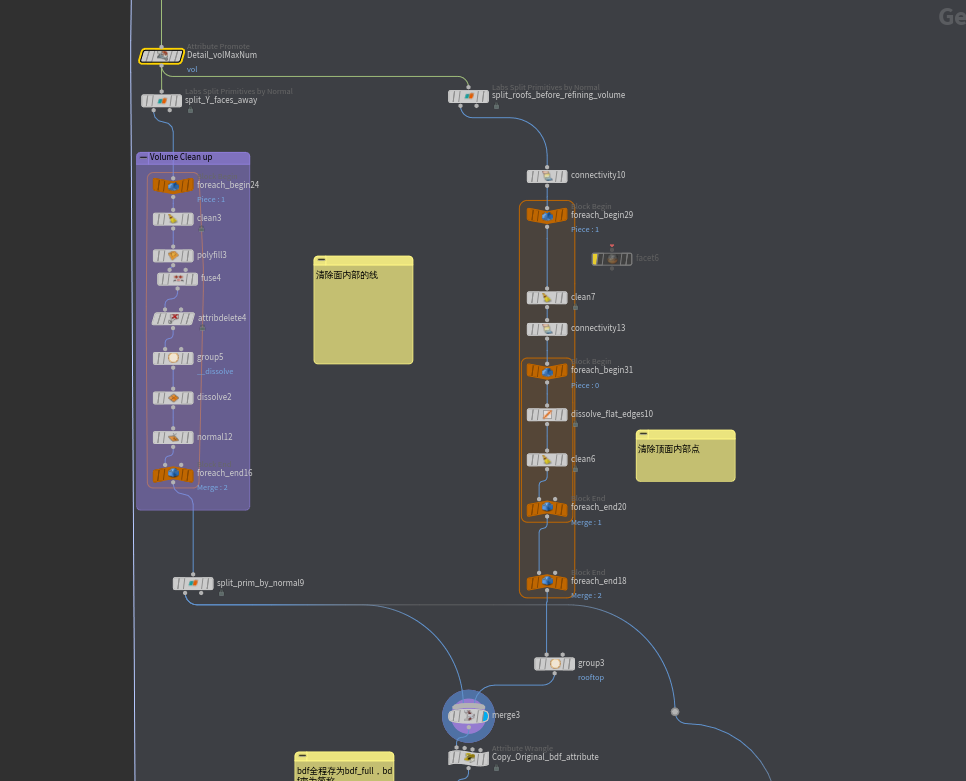
根据不同prim所在的vol不同,给不同的vol不同的颜色去标记它们,循环处理当前建筑的每一个vol。
@Cd = 0;
vector colors[] = {{1,0,0}, {0,1,0}, {0,0,1}};
@Cd = set(colors[i@vol]);
进入处理楼层高度的循环,这部分最重要的节点为:
Dct_Building_Volume_Slicing,也就是先计算一些体积相关信息,主要就是得到高度和由多少块(体或者bdf)构成的,通过输入1的bdf信息、以及vol(由多少bdf构成)信息,取到输入2中对应的bdf点上的信息,然后生成,因为是生成高度,这个简单介绍一下逻辑:
取到Dct_Levels中的Repeat数组代表是否可以重复此楼层,与height数组代表此楼层高度,楼层数量是通过Dct_LevelsGrammar得到的,比如 楼层为7,那么会把7层楼高相加起来 与 生成体积的高度相减,得到的差就为重复楼层的高度,然后我们便可以通过repeat数组知道那些楼层可以重复,用重复的楼层去填补与生成体积之间的高度差。最后在每个楼层处生成一个点云,将相应属性附着上去。得到:
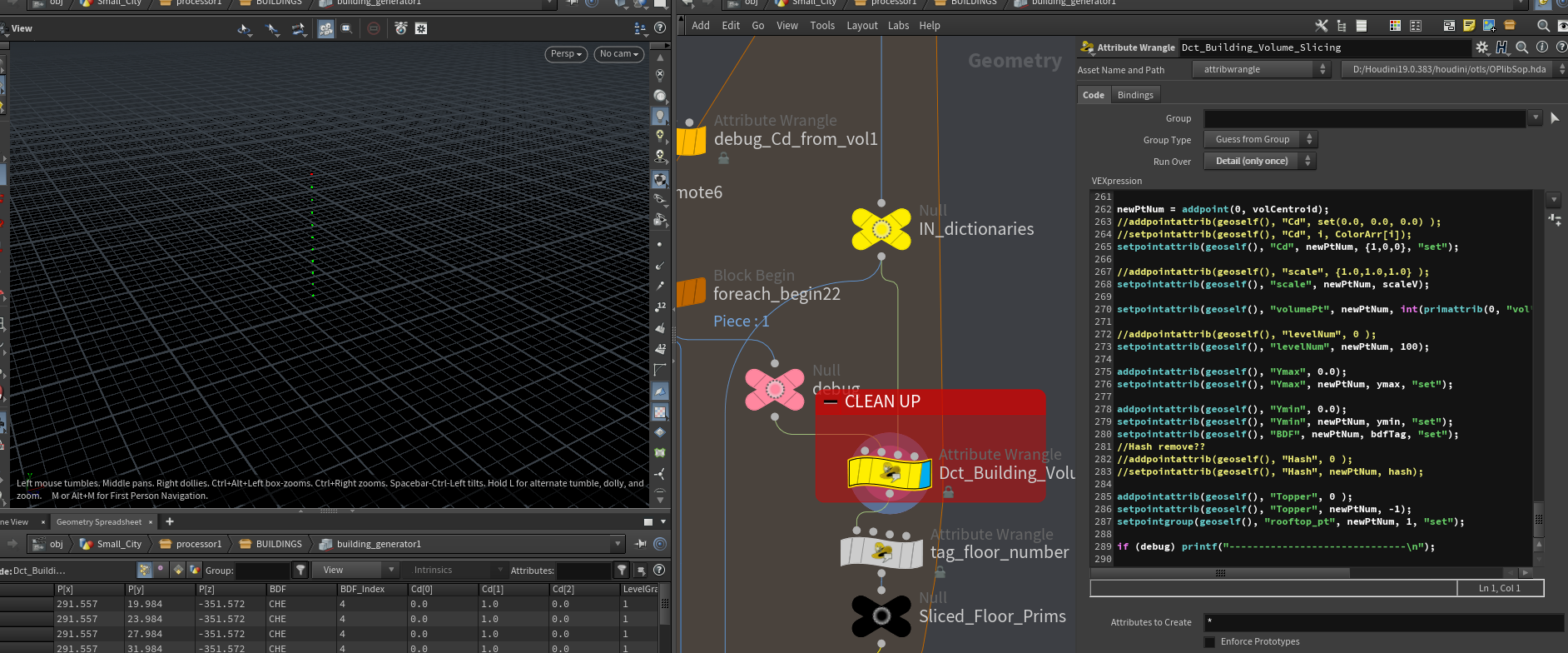
给每个点上 上一个i@FloorNum 属性,代表自己为当前vol的第几层。
通过volume_slicer这个subnetwork节点对每个点都对包围形状做切割,保留切割面的边缘线。给每个prim都给上对应属性包括,当前层数,是否为顶层,当前层的顶层为谁等。
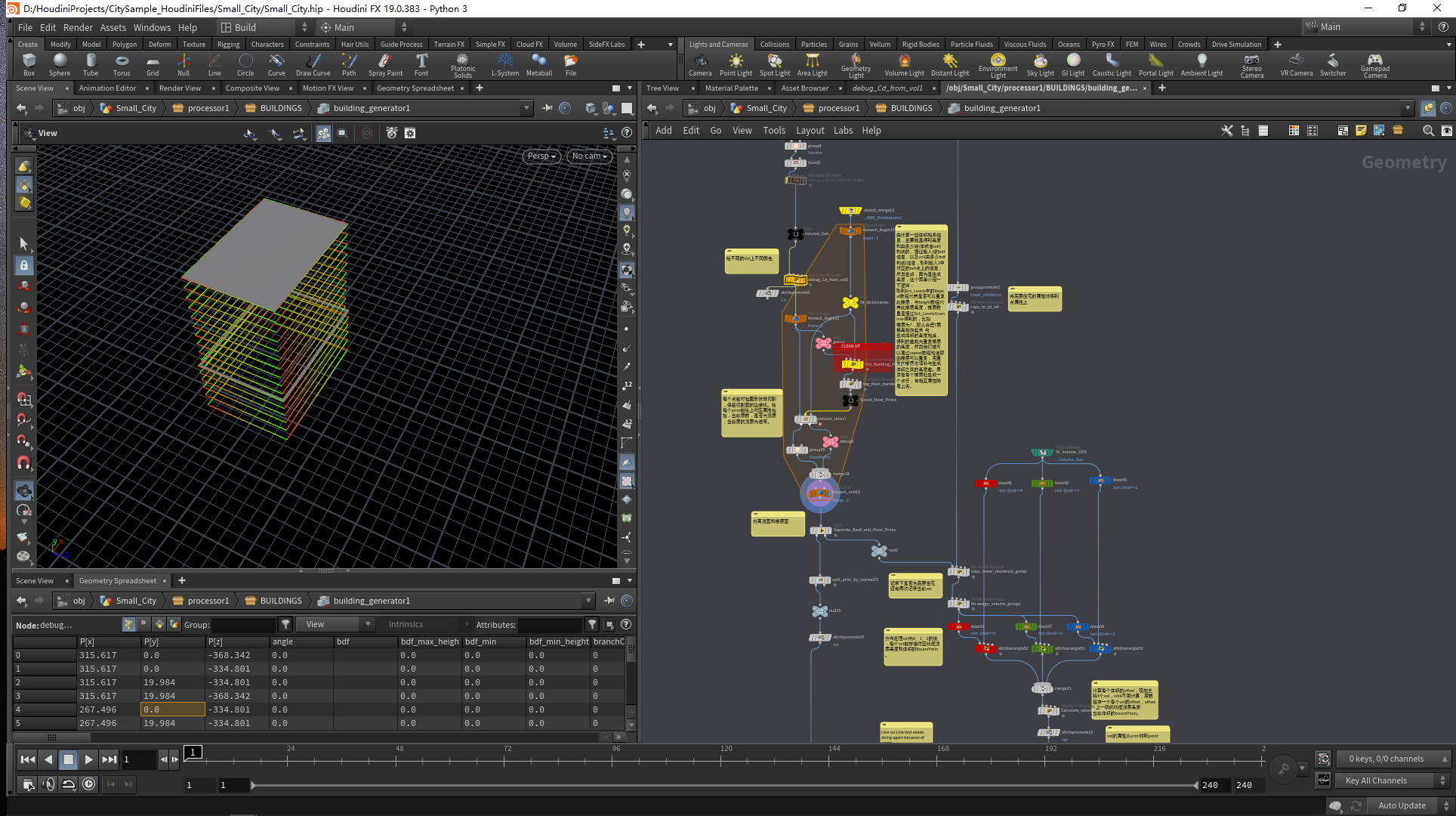
拿到结果后,我们需要把顶层和墙面分离开来处理。
拿到墙面数据之后,我们需要记录下是否为底层住宅 还有再次记录当前vol,分别处理vol为0、1、2的块,每个vol都存储对应线框顶层高度和体积的BoundYmin。
计算每个体积的offset,现在支持3个vol,vol0不用计算,用数组存一个每个vol的offset,offset = 上一级的线框顶层高度-当前体积的boundYmin。
将vol的属性从prim转到point,根据点上vol属性确定自己的vol,根据voloffset去@P.y+=offset[volindex],注意第二层再还得加上第一层的offset
因为移动过BDF所有每根线都会重新测试一下确定线框顶层。所以我们还需要处理线框顶层同样根据点上vol属性确定自己的vol,根据voloffset去@P.y+=offset[volindex],注意第二层再还得加上第一层的offset。
这回我们先关注线框顶层这条逻辑线,拿到偏移后的线框顶层之后我们需要通过BDF_Index找到对应的Dct_Roof,保存里面的对应属性,顶层的偏移以及缩放。通过Y轴高度来排序prim的顺序,越高的prim序号为0。标记出最高的顶层,要么Pos.y=maxRoofY,要么@primnum=0;将标记的顶层偏移对应BDF里面的Roof_Offset。
选择性是否输出没有缩放过的顶层,作为碰撞使用。
如果是被标记为最高顶层的Roof,那么将会沿着prim向内缩放Inset的值。根据BDF的subRoot中的Inset和offset做Y轴的偏移和向内缩放,合并Roof的模型与碰撞体便可以输出顶层啦。
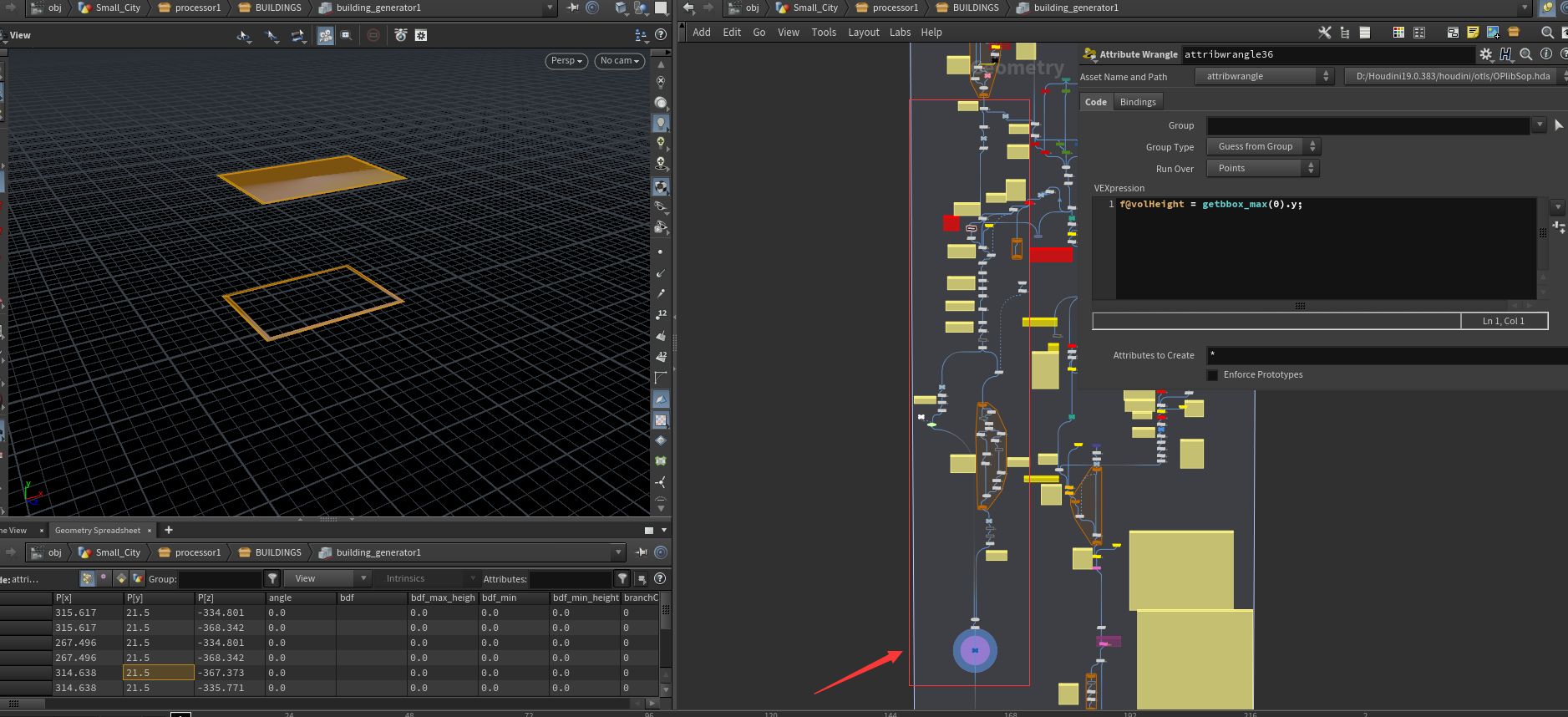
回到偏移过后的墙面线框。
通过BDFIndex找到对应的BDF,再通过每一层的LevelNum,去BDF中找到对应每一层的CornerCap,也就是每一层的角落是否使用角帽墙。将每条边的中点、以及指向的方向写入当前边所在的点属性中。
找到所有为Topper的prim,遍历第一个点周围5米内还有比他高的点,并且两个点所在的Prim中点相差距离不大,就移除当前Topper,其实就是找最高层。因为是分vol操作的,每个vol都会有一个Topper,当vol合并在一起的时候Topper也应该只剩一个。
之后我们需要找到每个角落的类型,所以我们分为两部分来处理,顶层墙面与非顶层墙面。
非顶层:
遍历每一个Prim上的每一个point,将prim的primnum和法线存储到point上,查找每一个点周围0.1m范围内是否还有其他点,如果有其他点那么cornerNormal为两点法线相加/2,如果没有cornerNormal为自身将cornerNormal属性存储在点上,每一个周围0.05m范围内还有其他prim,把周围是否有其他点,周围是否有其他prim都存在点上,如果不是顶层,那么primNormal = @N;
通过上面得到的每个点相邻prim数组,来判读当前点周围prim数量是否大于等于2,如果是,那么记录下每个prim[0]和prim[1]的中心点。如果小于2,那么根据这个点周边更远处是否有prim来决定当前点的CornerType。剩余的点就通过拿到自己上一个prim的中点以及下一个prim的中点,来根据
vector d1 = normalize(v@P – prev_p);
vector d2 = normalize( next_p – v@P);
d1与d2的夹角与CornerCap的值判断使用那种类型角落墙。
如果当前CornerType不为空的话,拿到当前点的相邻Prim,根据相邻prim的FacadeType属性决定当前点的CornerFacade的优先级。
顶层:
每条边和其他边做角度判断,删除不合格的边。将primId和pt顺序id存入点上,根据点旁边是否有其他点,如果有存下其他点的primid与pointid,如果没有都是-1,
也是通过上面得到的每个点相邻prim数组,来判读当前点周围prim数量是否大于等于2,如果是,那么记录下每个prim[0]和prim[1]的中心点。如果小于2,那么根据这个点周边更远处是否有prim来决定当前点的CornerType。剩余的点就通过拿到自己上一个prim的中点以及下一个prim的中点,来根据
vector d1 = normalize(v@P – prev_p);
vector d2 = normalize( next_p – v@P);
d1与d2的夹角与CornerCap的值判断使用那种类型角落墙。
如果当前CornerType不为空的话,拿到当前点的相邻Prim,根据相邻prim的FacadeType属性决定当前点的CornerFacade的优先级。
删除边上两点roofEdge都为0的prim
如果prim上只有两个点,那么将这两点的相互朝向NTM记录下来,还有两点的距离。
拿到当前点相邻prim,如果只有一个相邻prim的话,取得那个prim里面离当前点第二近的点上的NTM属性与当前点的NTM属性点乘判断方向,如果点乘结果小于-0.95,判断两prim的 长度如果当前prim长度>=相邻prim长度那么当前点位置为相邻prim上同序号点位置,否则就删除当前点与当前prim
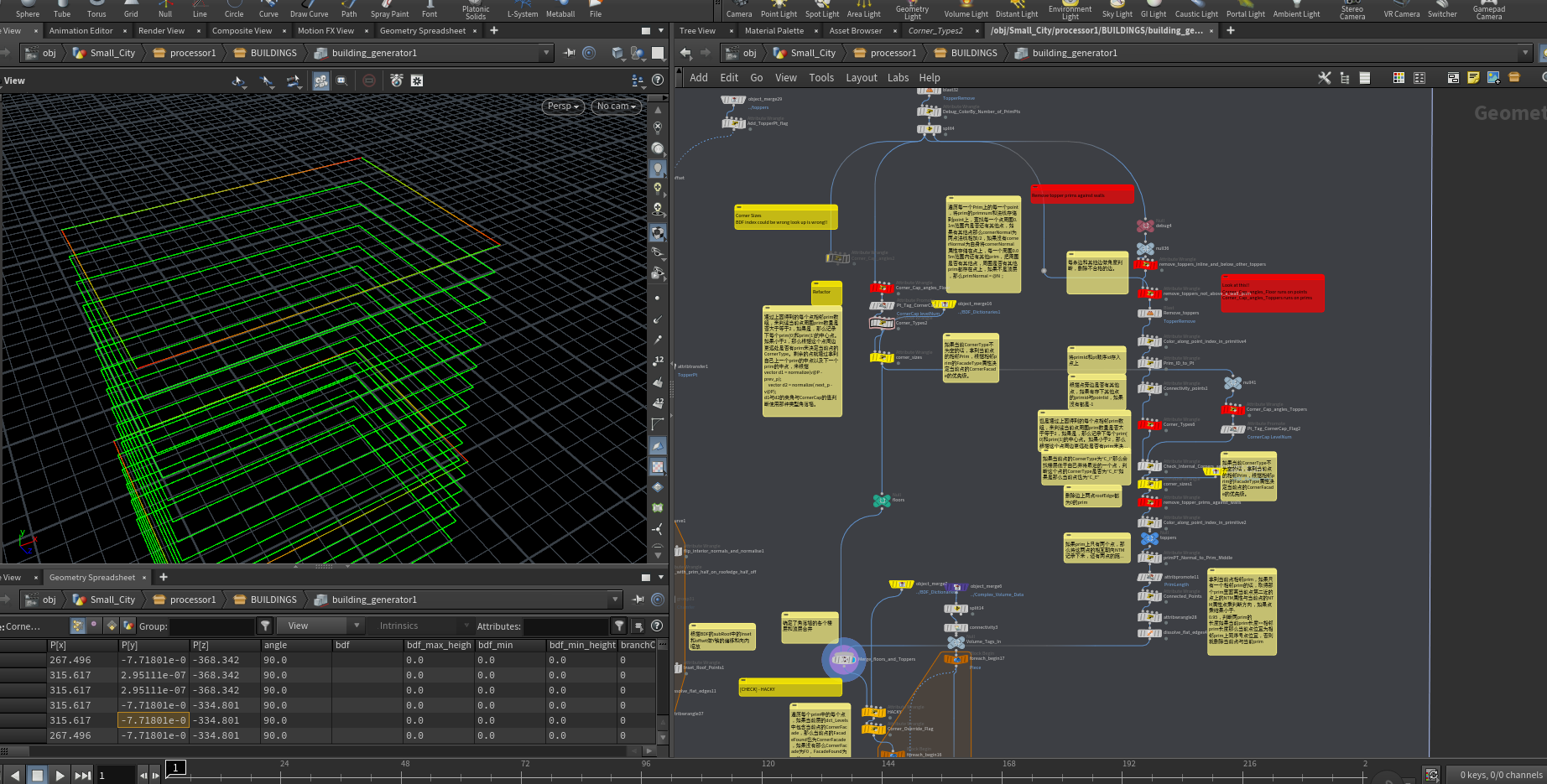
确定了角落墙的各个楼层和顶层合并
HACKY :遍历每个prim中的每个点,如果当前层的dct_Levels中包含当前点的CornerFacade,那么当前点的FacadeFound也为CornerFacade,如果没有那么CornerFacade为F0,FacadeFound为notfound。
下一个循环为Corner Override相关的操作,当前并没有Complex_Volume_Data所以跳过。
下面着几个节点就是整个HDA最重要的几个节点啦。
Shape_Grammar_Decomposition4:语法拆解节点,拆解并存储语法信息包括单个模块名称、重复单元、缩放单元、固定单元、单元尺寸信息等。
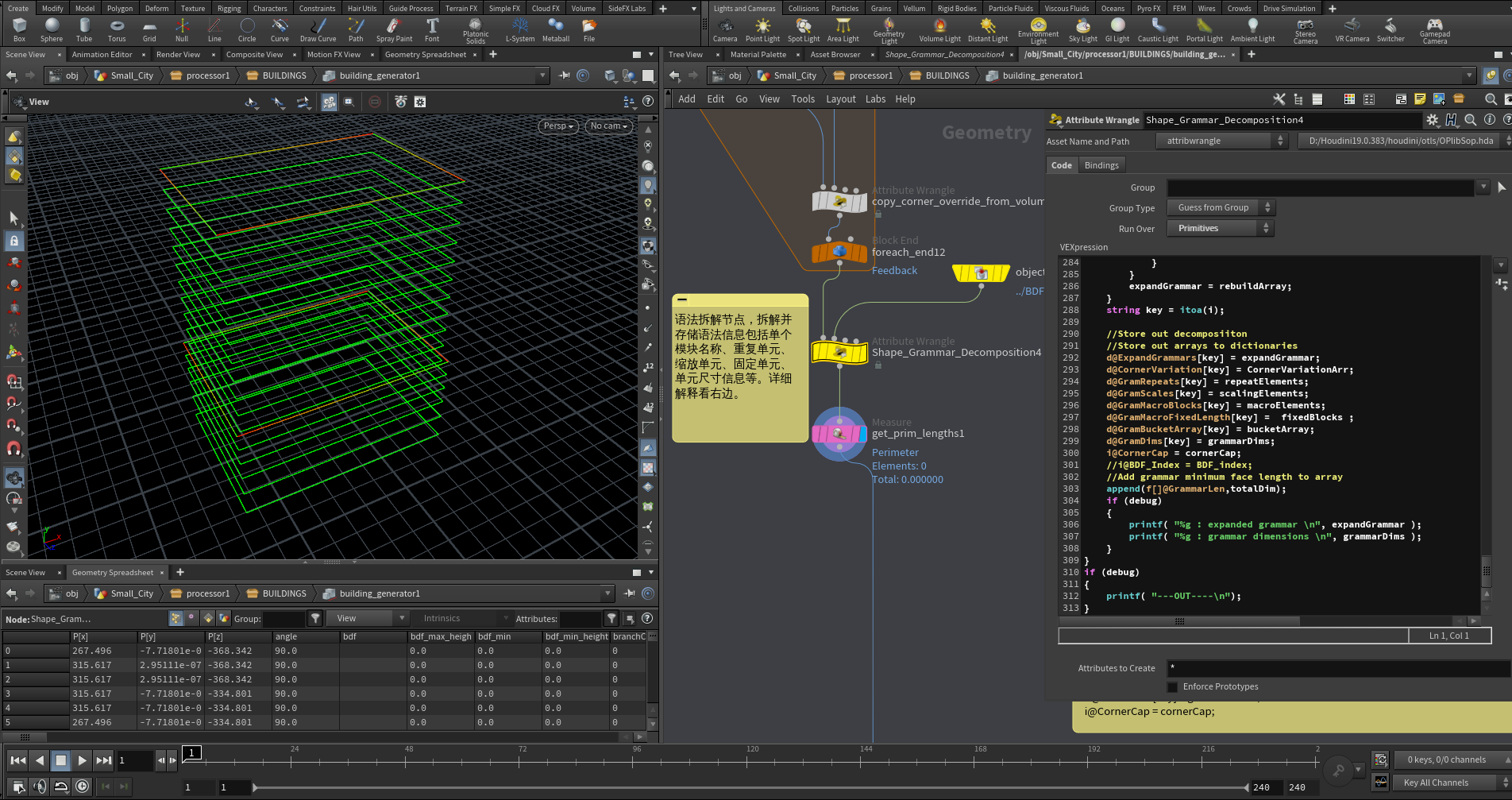
VEX逻辑大致为:
先加载当前BDF_index对应的所有dictionaries信息,以及当前prim的所有点和prim的level信息、primFacade信息。使用当前primlevel和primFacade找到对应的形状语法,如果找不到用F0作为默认primFacade得到对应形状语法。将形状语法存储到Grammars,之后我们得解析每个语法得到每个模块的长度,
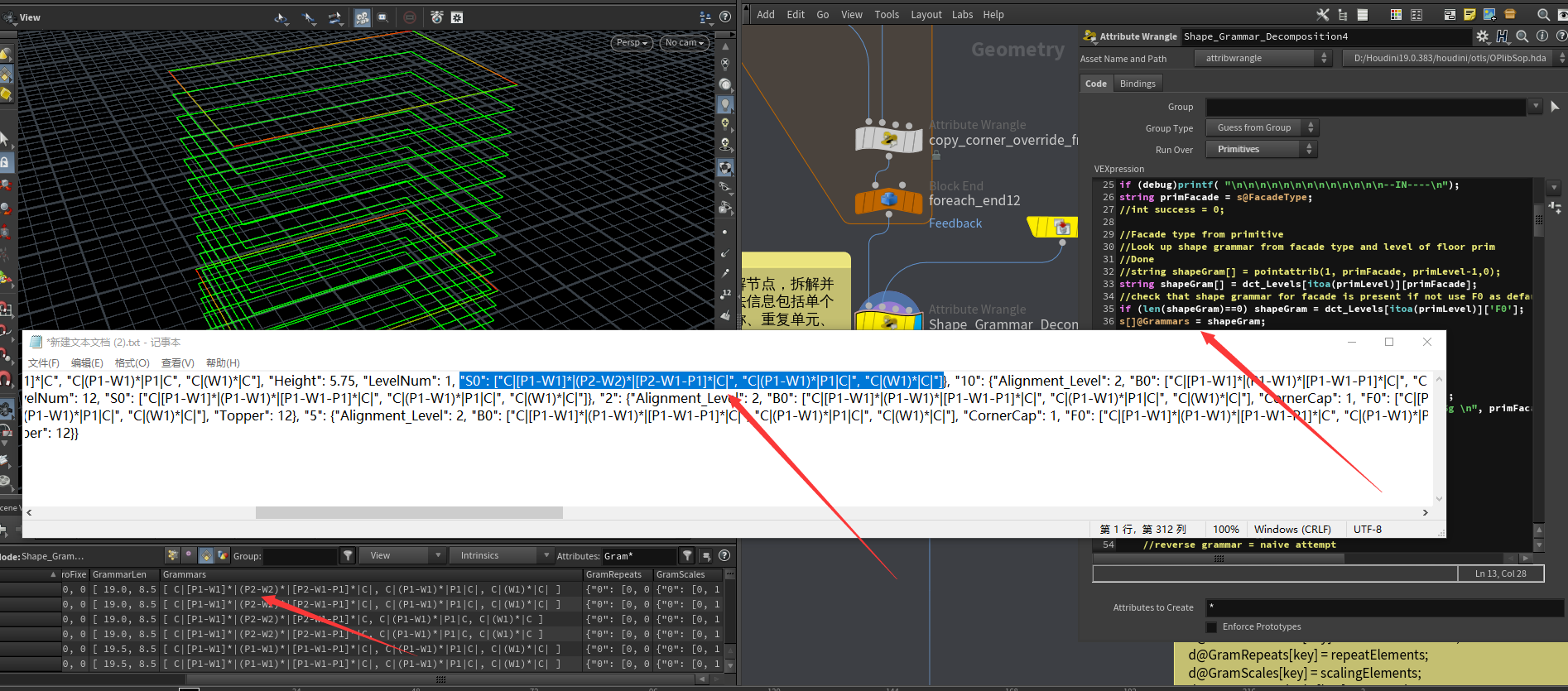
遍历每个gramEntry,gramEntry=Grammars[i]。创建一系列预先需要的属性包括CornerVariationArr[];repeatElements[];scalingElements[];macroElements[];fixedBlocks[];expandGrammar[];macroGrammar;macroFormat;bucketArray[];等这里主要的就是几个记录数组包括是否可以重复的元素、是否可以缩放的元素、是否固定数量的原始等。
一个gramEntry就是一个语法,比如:C | [P1-W1] * | (P2-W2) * | [P2-W1-P1]* | C,通过字符串分割split(gramEntry,"|")可以得到语法中的每一个语法单元C 、 [P1-W1] *、 (P2-W2) *等,也就是每个语法元素单元集合gramElements,语法元素 C、P1、W1、*等。
遍历每个语法中的语法单元中,也就是对遍历每个语法元素集合 gramElements。
这个gramElements可以分两种情况,一种是为C模块也就是角落模块,一种是墙模块,首先我们看C模块如果gramElements[0]=="C",这里主要记录C模块的len(gramElements)是否大于1,如果大于1那么记录下C模块的变体数量,CornerVariation=gramElements[-1],如果不大于1,那么变体为0,再将变体添加到CornerVariationArr中。
接下来就是看gramElements是否存在宏元素macroElement,也就是是否有"-",find(gramElements, "-") > 0,如果有,我们macroElements添加一个为1也就是true的值,bucketArray根据当前有n个"-"字符添加上n+1个当前gramElements的index。 如果没有macroElements添加一个为0的值,bucketArray添加一个当前gramElement的index。
检测gramElements是否存在重复单元find(gramElements, "(") >= 0,如果有就在当前append(repeatElements, 1);没有就append(repeatElements, 0);,同样检测gramElement是否存在缩放单元find(gramElements, "") >=0,如果有就在当前append(scalingElements, 1);没有就append(scalingElements, 0);检测gramElements是否存在固定单元find(gramElements, "]") >=0,如果有就在当前append(fixedBlocks, index); int index = atoi(split(gramElements,"]")[1]);,“]”后一个元素就是固定循环次数。,没有就append(fixedBlocks, 0);。
for( int i = 0; i < gramArrLen; i++)
{
int CornerVariationArr[];
string gramEntry = shapeGram[i];
string gramElements[] = split(gramEntry,"|");
//reverse grammar = naive attempt
//gramElements = gramElements[::-1];
//loop through and look up grammar and level to build dimension array
//printf( "%g \n", gramElements);
//build repeating array, macro array, non-repeating macros
int repeatElements[];
int scalingElements[];
int macroElements[];
int fixedBlocks[];
string expandGrammar[];
string macroGrammar;
string macroFormat;
int bucketArray[];
string format;
int grammarType;
int Importance[];
int indexCount = 0;
for ( int ii = 0; ii < len(gramElements); ii++)
{
format = strip(gramElements[ii]);
grammarType = 4;
//check for corner variations
//ideally this is generic to work with all modules
//look up corner grammar via corner priority
if (format[0]=="C" )//&& @primnum == primToTest)
{
if (debug) printf("PrimID: %g\n", @primnum);
if(len(format)>1)
{
append(CornerVariationArr, atoi(format[-1]));
//format="C";
}
else append(CornerVariationArr, 0);
if (debug) printf("Corner Variation Array: %g\n", CornerVariationArr);
}
//check for macros
if (find(format, "-") > 0)
{
append(macroElements, 1);
string elements[] = split(format, "-");
for(int h = 0; h < len(elements); h++)
{
append(bucketArray, indexCount);
}
indexCount++;
}
else
{
append(macroElements, 0);
append(bucketArray, indexCount);
indexCount++;
}
//check for repeating modules
if (find(format, "(") >= 0)
{
append(repeatElements, 1);
grammarType = 1;
} else append(repeatElements, 0);
if (find(format, "*") >=0 )
{
append(scalingElements, 1);
grammarType = 1;
} else append(scalingElements, 0);
// check for fixed macro repetition amount
if (find(format, "]") > 0)
{
int index = atoi(split(format,"]")[1]);
append( fixedBlocks, index);
grammarType = 2;
}
else append( fixedBlocks , 0);
append(Importance, grammarType);
}
//debug
if (debug==2)
{
printf( "%g : repeating\n", repeatElements);
printf( "%g : scaling\n", scalingElements);
printf( "%g : macro blocks\n", macroElements );
printf( "%g : fixed repeat macro block\n", fixedBlocks );
printf( "%g : bucket array\n", bucketArray );
printf( "%g : Importance\n", Importance );
}
再创建一些预先需要的属性主要是grammarDims[]、 totalDim、module这几个,也就是当前单个模块的尺寸、单个语法总模块的总大小、当前模块名称。使用字符串分割expandGrammar = split(gramEntry, "|()[]-");遍历每一个语法模块。module = strip(expandGrammar[j]);。首先判断当前模块(语法元素)是否为墙角模块if (module[0]=="C" ),如果是,那么判断一下当前是否为第一个墙角模块,如果为第一个,角落模块我们遵循墙角模块的点模块属性优先级大于prim模块属性,所以我们将点属性上的CornerFacade、module给当前模块,判断面上的CornerFacade是否等于点上的CornerFacade,如果不等于,那么我们根据点上的CornerFacade属性去dct_level对应当前level中找到对应的第一个墙角模块,把当前展开的模块替换为点属性对应的模块expandGrammar[j]=cornerFacadeGrammarArr[0];。如果当前不是第一个墙角模块,那么也是一样点属性优先于prim属性不同的是,替换的模块为1号点属性对应的最后一个墙角模块。expandGrammar[j]=cornerFacadeGrammarArr[-1];再根据墙角模块的后缀处理不同的变体。
之后我们判断当前模块是否在对应level的模块字典中存在isvalidindex(dct_Modules[itoa(primLevel)], module,如果存在我们找到对应模块的尺寸数据Mod_Dim,存入grammarDims数组中,totalDim累加当前尺寸既可。最后在将得到的数据存储到点上。
d@ExpandGrammars[key] = expandGrammar;
d@CornerVariation[key] = CornerVariationArr;
d@GramRepeats[key] = repeatElements;
d@GramScales[key] = scalingElements;
d@GramMacroBlocks[key] = macroElements;
d@GramMacroFixedLength[key] = fixedBlocks ;
d@GramBucketArray[key] = bucketArray;
d@GramDims[key] = grammarDims;
i@CornerCap = cornerCap;
到这一步,BDF语法的预先处理工作就结束了,我们需要使用Measure节点来测量每一面墙的实际长度,接下来就是要根据墙的实际长度去正式的生成建筑模块点来匹配当前墙面。
重点VEX节点:Add_Module_Types
首先定义两个函数CheckFit和PlacedLength,CheckFit主要是给一个模块长度数组(记录单个模块的尺寸),每个模块数量数组,和一个长度值,返回值为长度值-(所有模块数量对应模块长度)。PlacedLength则是直接输出总的模块长度(所有模块数量对应模块长度)
function float CheckFit(float BucketDims[]; int TempBuckets[]; float faceLength)
{
//total placed modules
float placedLength = 0;
for (int i = 0; i < len(TempBuckets); i++)
{
placedLength += (BucketDims[i] * TempBuckets[i]);
}
//printf( "placed Length:%g \n", placedLength);
return (faceLength - placedLength);
}
function float PlacedLength(float BucketDims[]; int TempBuckets[])
{
//total placed modules
float placedLength = 0;
for (int i = 0; i < len(TempBuckets); i++)
{
placedLength += (BucketDims[i] * TempBuckets[i]);
}
//printf( "placed Length:%g \n", placedLength);
return (placedLength);
}
之后从节点属性中取得并创建我们需要的一系列变量###
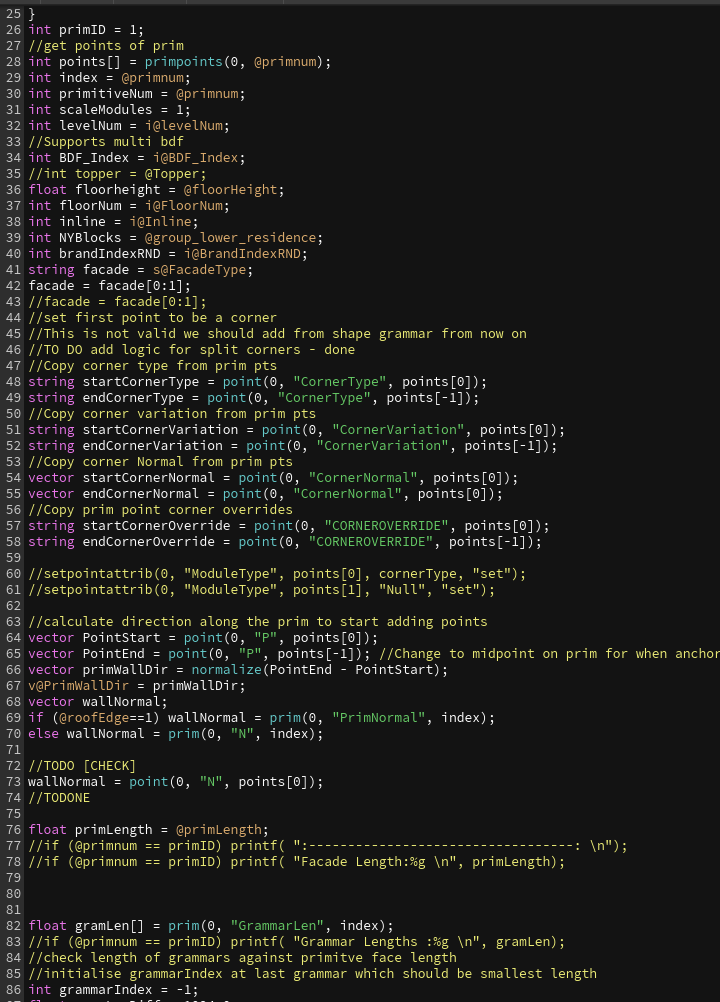
因为之前使用Measure测量过所有prim的长度,所有我们要做的就是将我们的语法长度与当前墙的实际长度匹配。
遍历我们的GrammarLen[],找到语法长度(GrammarLen[i])<=墙面长度,并且相差最小的一个。如果都不满足语法长度<=墙面长度,那么就用最后一个语法长度。将当前最匹配的GrammarLen[i]的index存储起来,好通过索引去找到对应的语法的其他属性。key=grammarIndex。通过当前所在的@primnum与Key我们可以获得对应图元中对应语法的信息并创建对应的属性变量。
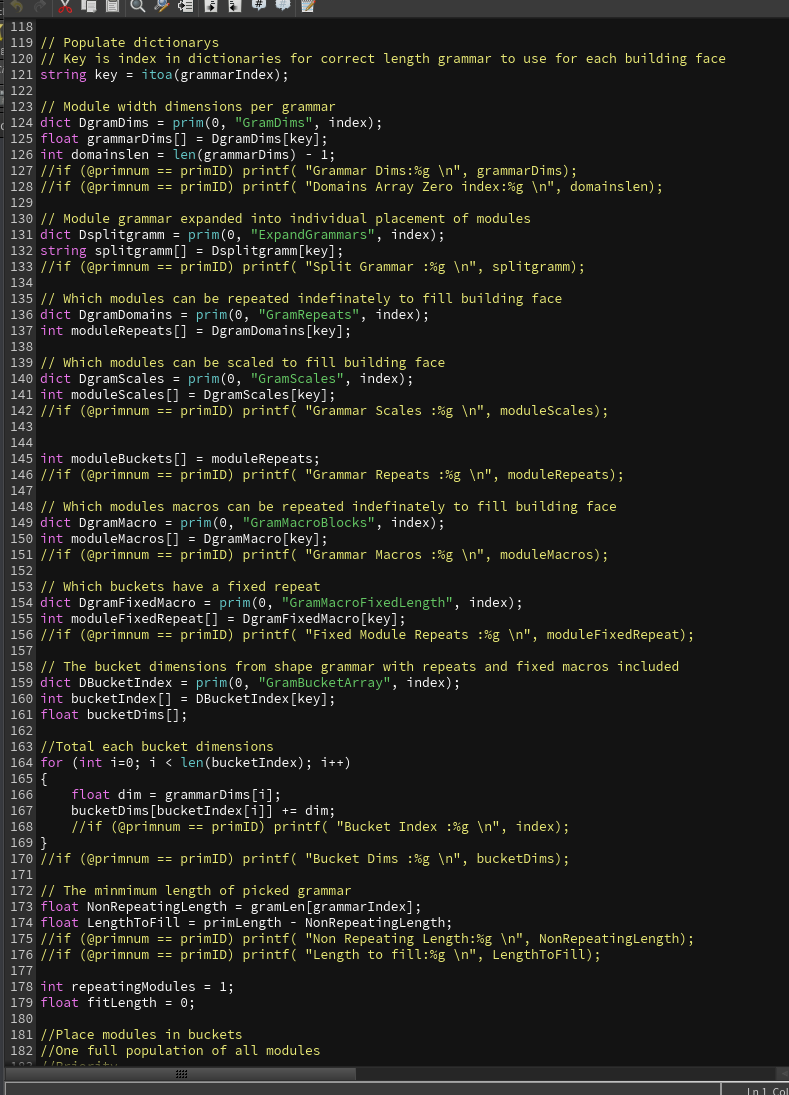
包括当前语法的每个模块尺寸、每个模块是否可扩展、每个模块是否可以重复、是否可以缩放、每个模块是否为固定重复、每个模块的固定重复次数等等。得到对应的语法所有Key之后,我们还需要当前语法中的每个语法单元的长度,根据每个语法单元中的语法元素所在的index,在GramDims[]找到当前语法元素对应的模块长度。
接下来就准备填充这个墙面长度,先使用当前语法长度去填充也就是默认每个语法单元数量都为1,这样是有概率成功的,之后的顺序便是先将固定重复语法单元一个一个的添加回来,CheckFit当前墙实际长度减去添加过后的语法长度是否大于等于0,如果小于0也就是超出墙实际长度啦,那么将添加的语法单元减去。之后再到可无限重复单元也是如此操作。通过可重复单元将当前语法长度和实际墙面的距离差压缩到最小,之后的距离填补就需要用到我们的缩放模块啦,通过缩放模块的缩放操作来填满最后的距离差,使得当前语法长度与实际墙面长度一致。
创建一个新的变量记录下当前语法长度与实际墙长度差float LengthRemaining = CheckFit(bucketDims, tempBuckets, primLength);,遍历所以语法元素把可当前可缩放的语法元素的长度记录下来作为一个可缩放的总长度(scalableModuleCoverage),因为缩放的话并不是单独的缩放一个模块,我们会将所以可以缩放的模块统一缩放,使得缩放过后的 可缩放模块总长度 = 原可缩放模块(scalableModuleCoverage) + 剩余长度差( LengthRemaining),所以我们只需要得到剩余长度缩放比例 scaledelta = LengthRemaining / scalableModuleCoverage; ,最后便是 最终可缩放模块总长度 = 原可缩放模块(scalableModuleCoverage) * (1+ scaledelta);这样就能完全填充满实际的墙面长度。
因为最后需要生成每个点的位置所以需要预先存储一个moduleOffsets,moduleOffsets[i] = grammarDims[i] + (moduleScalesDelta[i] * grammarDims[i]);。接下来我们就先定义一系列生成点需要的属性比如offsetTotal、scale、currentMacro等等就可以开始生成点啦。循环遍历每个语法元素。拿到每个元素的属于那个语法单元,以及当前语法元素的基础长度、当前语法单元的数量等。
遍历当前语法元素的所在的语法单元重复的每个单元。记录下当前所在语法单元id,循环遍历 如果当前记录的语法单元id == 当前所在的语法单元id 就继续循环,循环内容为 记录循环次数,当循环超过500就推出避免死循环,记录当前索引指向的语法元素所对应的模块名称,如果名称的第一位字符为“C”,那么modlue变量为C,判断当前是否为第一个放置的模块,如果是那么offset属性为0;如果不是,那么当前offset为预先记录的moduleOffsets[],索引为前一个语法元素的索引,然后将当前语法元素索引记录在moduleIndexPlaced[]中供一下语法元素使用,记录下当前语法元素的缩放和offsetTotal += offset; offsetTotal就表示上一个语法元素的末尾,也就是当前语法元素的起始位置。将当前语法元素起始位置存储到modDistanceOnPrim[],新建一个新的point 将这个点添加到当前prim中,设置这个point的属性,这个点就是一个当前语法元素也就是一个模块。
append(modulePtsAdded, newPtNum);
//?
setpointattrib(0, "CornerType", newPtNum, "", "set");
setpointattrib(0, "CornerNormal", newPtNum, {0,0,0}, "set");
//?
setpointattrib(0, "Corner", newPtNum, moduleCount, "set");
moduleCount +=1;
setpointattrib(0, "P", newPtNum, (PointStart + (primWallDir * offsetTotal)), "set");
setpointattrib(0, "N", newPtNum, wallNormal, "set");
setpointattrib(0, "ModuleType", newPtNum, module, "set");
setpointattrib(0, "ModuleIndexOnPrim", newPtNum, len(modulePtsAdded), "set");
setpointattrib(0, "scale", newPtNum, scale, "set");
setpointattrib(0, "offset", newPtNum, offset, "set");
setpointattrib(0, "ModDimZ", newPtNum, modDimZ, "set");
setpointattrib(0, "levelNum", newPtNum, levelNum, "set");
setpointattrib(0, "FloorNum", newPtNum, floorNum, "set");
setpointattrib(0, "Height", newPtNum, floorheight, "set");
setpointattrib(0, "PrimID", newPtNum, @primnum, "set");
setpointattrib(0, "FacadePt", newPtNum, facade, "set");
setpointattrib(0, "lot_ID", newPtNum, i@lot_ID, "set");
setpointattrib(0, "class", newPtNum, i@class, "set");
setpointattrib(0, "NYBlocks", newPtNum, NYBlocks, "set");
setpointattrib(0, "CornerVariation", newPtNum, "", "set");
setpointattrib(0, "BrandIndexRND", newPtNum, brandIndexRND, "set");
//[CHECK]set grammar index to -1 by default
setpointattrib(0, "GrammarIndex", newPtNum, -1, "set");
setpointattrib(0, "CORNEROVERRIDE", newPtNum, "", "set");
setpointattrib(0, "BDF_Index", newPtNum, BDF_Index, "set");
setpointattrib(0, "BDF", newPtNum, s@bdf, "set");
最重要的建筑点生成部分大致就这些拉。(真的好多一个VEX500行,让我见识到辣什么叫做专业)
拿到生成点之后,我们还需要单纯处理一下一楼的点,遍历每个LevelNum为1的prim,Point上存储离当前点最近的入口的距离,存储离当前点最近的角落的距离。
删除重复的90度的角落模块
根据当前的模块类型s@ModuleType为C的角落模块,在根据角落类型s@CornerType选择更准确的角落模块类型。